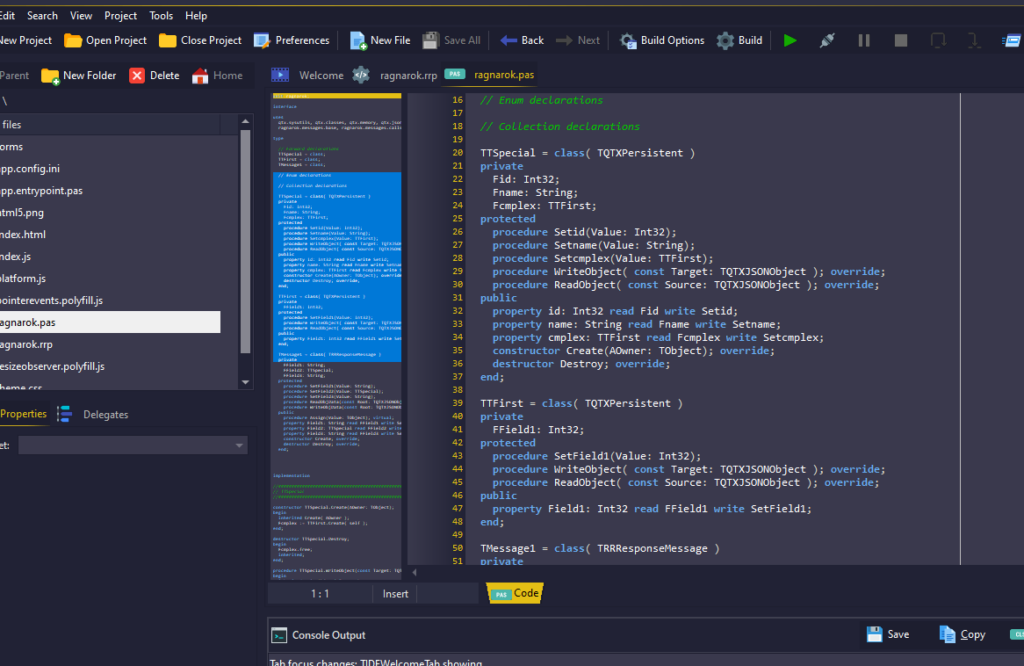
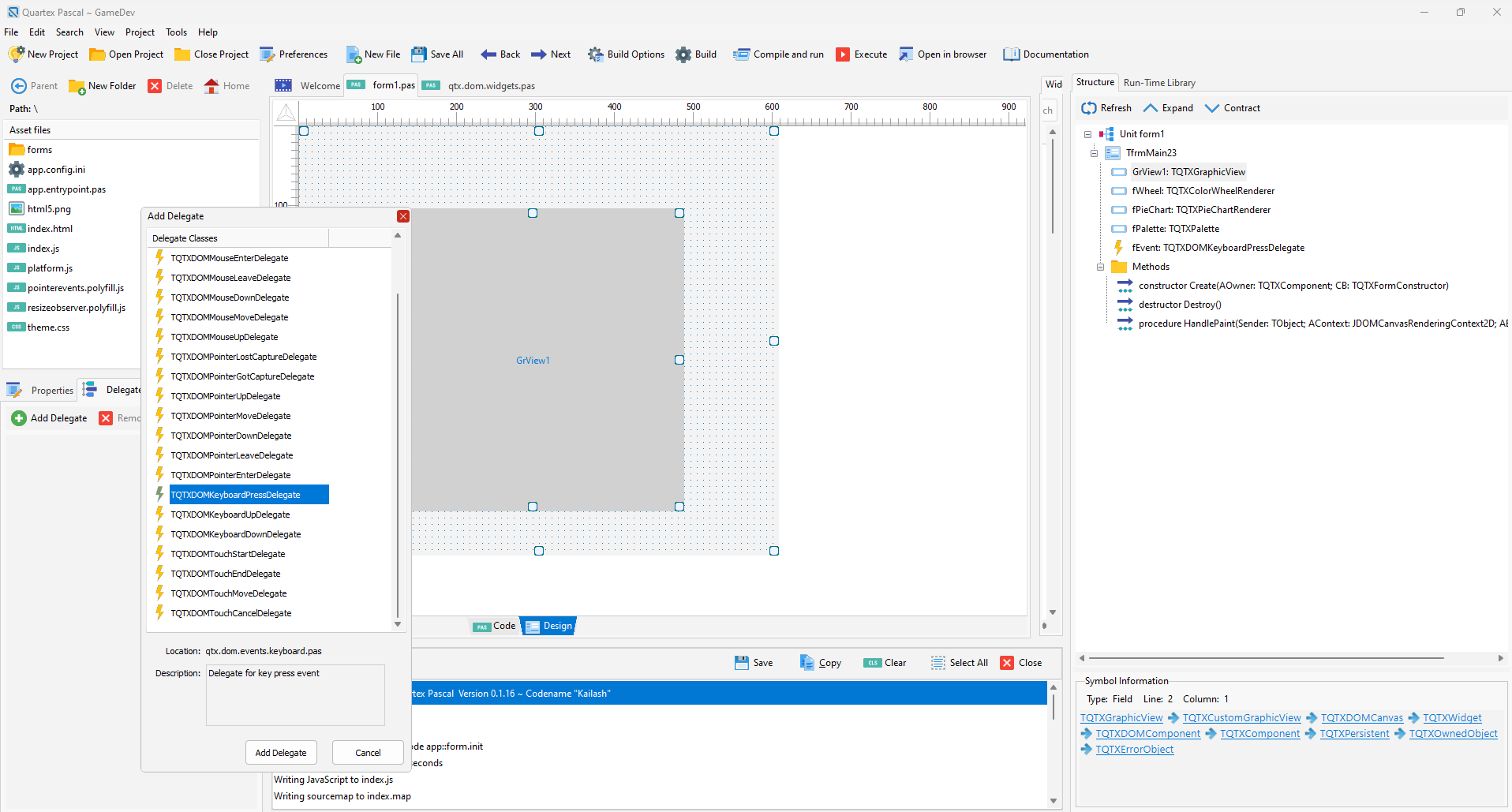
Hot on the heels of our initial release we have a few fixes. Mostly minor things but definitively things we missed on Monday. Thankfully the IDE has a lot of tooling inside, so fixing these things and adding suggested functionality was quick and easy.
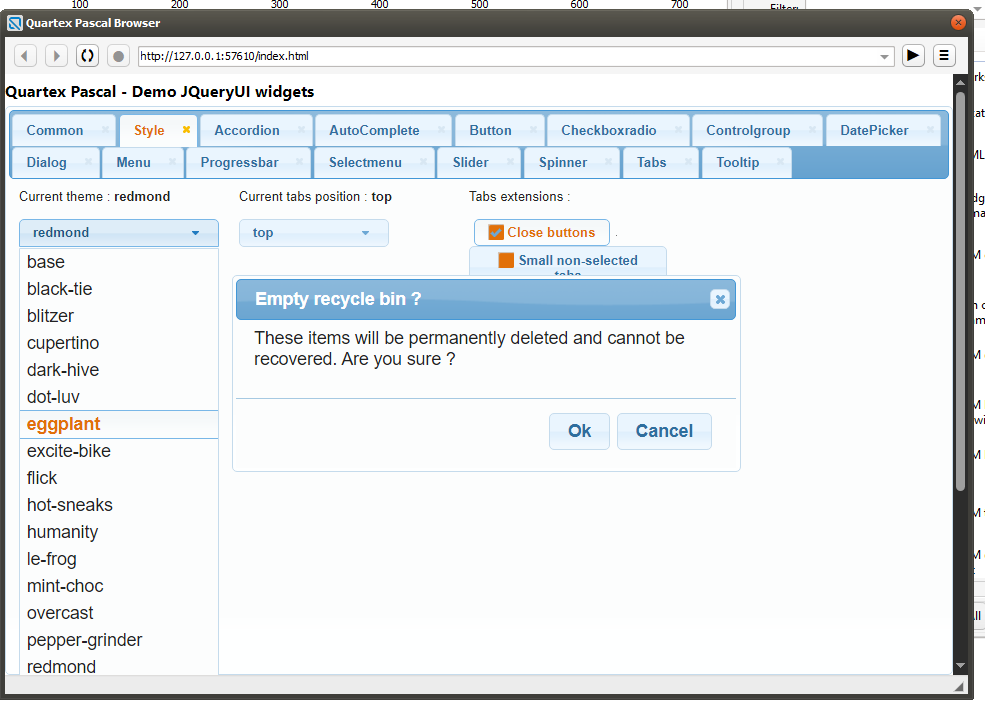
A couple of handy dialogs Delphi developers are used to have been added, like Shift + F12 etc
We are aiming at having the hotfix out friday at the latest.
Issues fixed
A focus issue when pressing F12 to toggle between code/form is taken care of
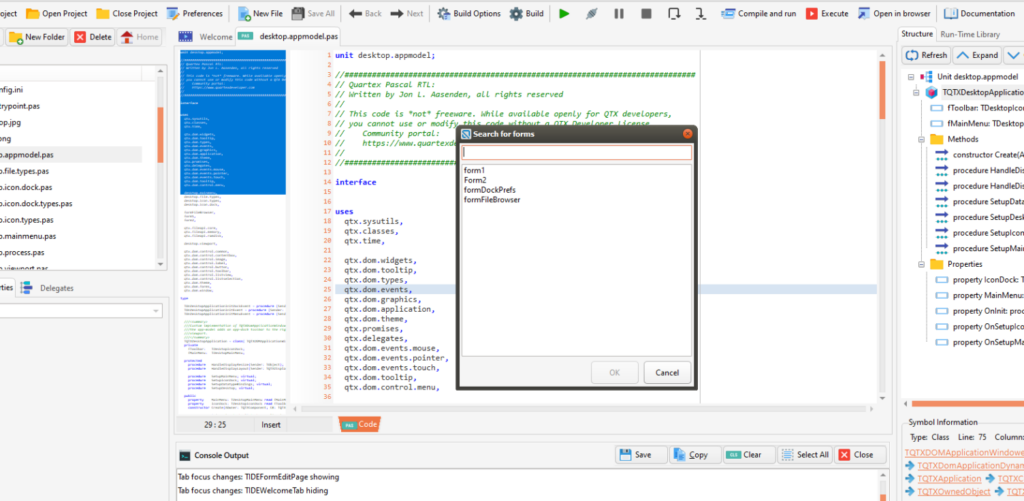
Shift + F12 now brings up a quick-search dialog, just like delphi
CTRL + F12 will bring up a similar quick-search unit dialog, just like delphi
Dependencies on pointer and resize polyfill js-files is now gone, they were purely there to support older webkit browsers, and are now obsolete.
Removed said dependencies from the template HTML files
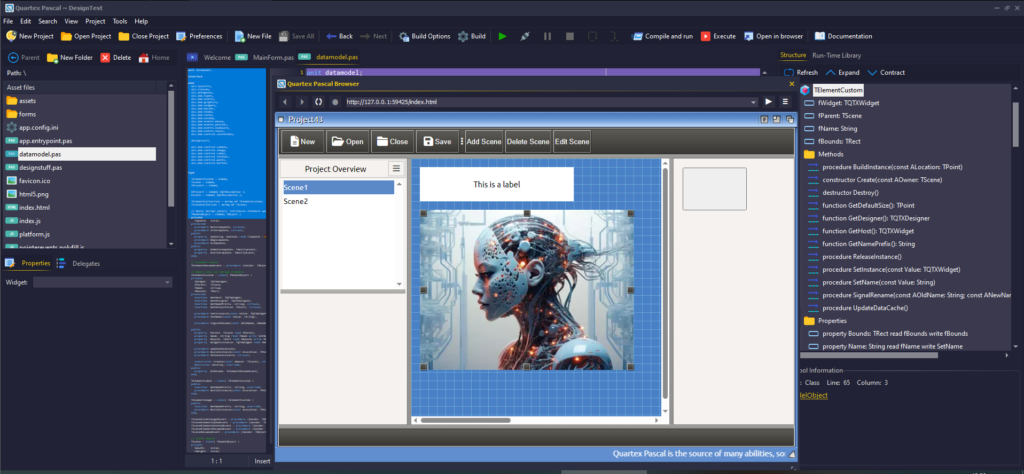
Fixed an issue where “New form” did not set the correct displaymode + positionmode. This should be absolute + inlineblock
Fixed a problem with gamepad delegate classes not being initialized properly
Added gamepad delegates to TQTXGraphicView so they can be easily hooked up in the 2D game project type
Gone over all project types and removed polyfills and set new default values. Also removed units that dont really need to be in the uses clause.
Fixed the DOSBOX demo, it needed some love and a custom css rule to define the virtual machine display size (one of the first demos we had, so it was old!)
Removed test projects that should never have been included
Fixed a toolbar resize issue. If the screen resolution is too small, the toolbar breaks to two lines, but autosize doesnt function, hiding some buttons. This is actually a Delphi bug. I implemented a resize fix for it.
Default IDE theme changes to light for simplicity sake (no colors issues with “new project” dialog, damn Delphi VCL styling missing category elements).
Two units belonging to the DOM namespace had been misplaced in common, files are now moved to the correct package.
Rebuildt helpfiles with more topics added. A pdf will be made available for download separately.
Fixed a small attachment issue with the debug process.
.. and a few more!
We are going to add better version checking for the packages, this way we can omit packages that already exists from the update window.
Its probably wise that we add a check that node is installed before you can hit the execute button on node projects.
It is with much joy that we finally release version 1.0 of Quartex Pascal! It represents three years of continuous development, and over a 1,5 million lines of streamlined, hard-core programming!
Quartex Pascal is very much ‘the road less taken’ in terms of engineering. A product that compiles object pascal to JavaScript, has its own RTL (runtime library) with hundreds of classes that interface with both the DOM and NodeJS. A system that has its own independent IDE with debugging, package support, form design and much, much more!
Quartex has several application models suitable for various program types
Just the beginning
This is just the beginning of the journey, and we do not intend to rest of our laurels. Updates and improvements will be frequent, as will new and exciting packages, project types and ready to use code.
Next up is non-visual components and datamodules, followed by database components – which brings drag & drop development to NodeJS and Deno. More advanced features and visual components, more packages, more wrappers and more code generation. Doing full scale applications for the browser will never be the same!
Manage your licenses as you see fit between your computers
We hope you find our work useful and see the potential in Quartex, especially when planning to implement web versions of your existing desktop applications.
Thank you
Jon-Lennart Aasenden Kjell O. Hove Quartex A/S, Norway
It’s a brand new year and we are working at full steam to get QTX out the door! We had hoped we would be ready in december, but the back-end has taken more time than we hoped.
The delay is largely due to how single-sign-on needed to work through several layers. We wanted to avoid having two sign-on steps, where you first had to login to our website (wordpress) and then a second login for the customer portal. That took a lot of digging through OAuth and OIDC, creating our codebase for this (in QTX ofcourse) and moving the website to our own servers.
The customer portal will be based on our desktop system, making it easier for our customers
We also implemented a full MariaDB / MySQL driver for node.js, which is now a part of our RTL (more DB engines will follow). And we dug into node.js clustering and have made strides in the node.js application model(s) that you can also use.
Status
The IDE is more or less finished (99.99%). The final step for the IDE is that it needs to be linked with our back-end service for license management – which we are implementing right now. We had basic CRUD done before xmas, and right now we are implementing the server REST API that talks to the database and exposes methods to the clients. This is the same API that the IDE will call with regards to license management – and also with regards to commercial packages (those that users sell through our system, which is optional ofcourse).
One of the new demos is a form designer implemented in QTX
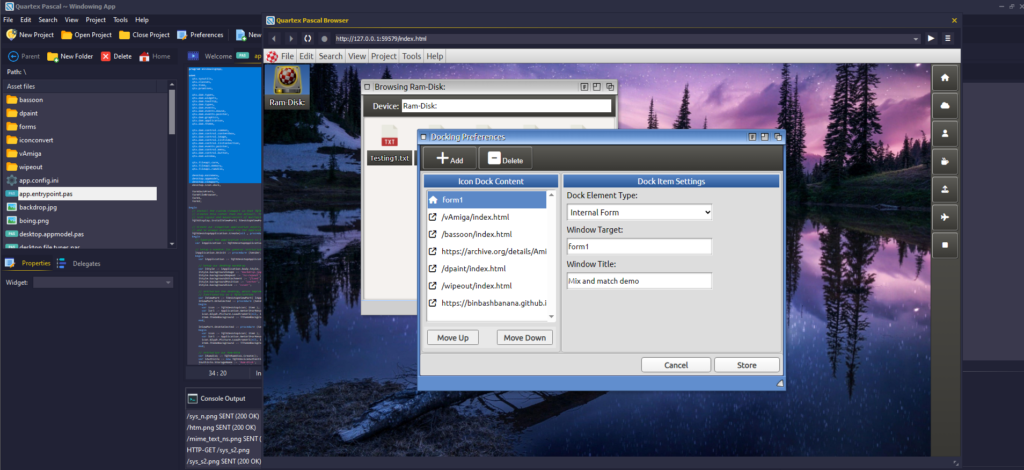
The pretty face on all of these services and tech is our desktop. When you login to our website as a customer, you will be greeted by the Quartex Desktop, and will be able to access everything you need from there. Your customer info, your licenses, the forum, bug reporting — it will all be available as separate desktop applications. Making it a lot easier for the customer to navigate, and also simplifying further development for us.
We probably could have solved this faster by using pre-fabricated tech — but we feel it would undermine our product if we used something coded in C# or C/C++. The entire point of QTX is to make rapid application development a reality, and that means eating the food we serve. Using our own tools to implement our solutions.
On our ticket list now there are only a handful of items left (literally below 10), tickets that were reported after the previous backer build. Minor things like refreshing the property inspector when switching tabs. Most of these were fixed before xmas, and while one of us works on the server API, the other will soon start on the desktop interface that unifies everything.
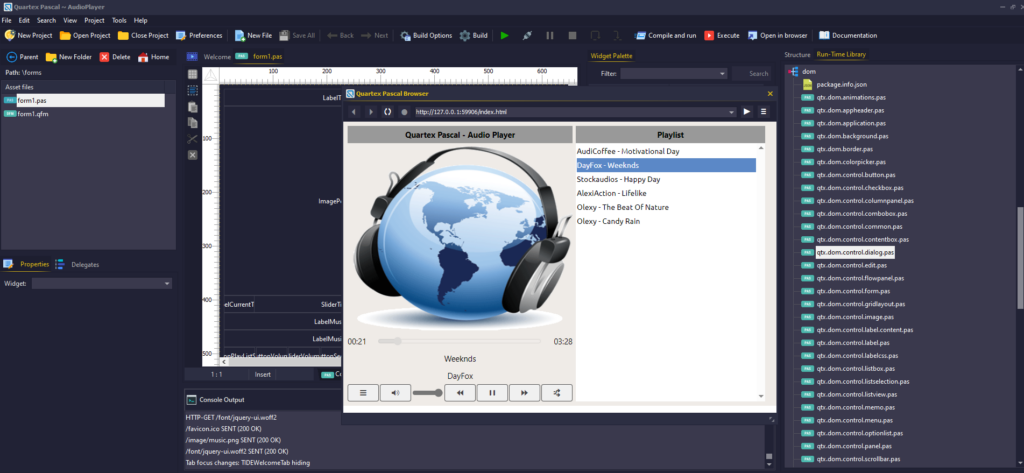
Fun and interesting demos by our backers, such as this fully features music player!
This desktop interface is not just for our customers, but also for ourselves. In short there will be 3 layers of functionality:
Customer
Retailers around the world
Admin access (for us)
I am glad we took the time to implement the different application models, even though most of it is not immediately visible. It saves us a lot of time now! Each desktop application (e.g forum, customer info, retail statistics and sales reports etc) will be implemented as separate projects. Using forms, toolbars and all the widgets we have spent so much time creating. All that non-visual code with features that are not immediately available in stock HTML/JS now comes into play at full force. The full might of object pascal hits hard!
Features and fixes
Since it’s been a while since we posted any official news outside the closed development channels, the list of features and fixes is quite long. We have squashed bugs that have been reported, and also gone over the components in the RTL quite extensively. Adding custom delegates where needed, or classes and methods where we felt it was needed.
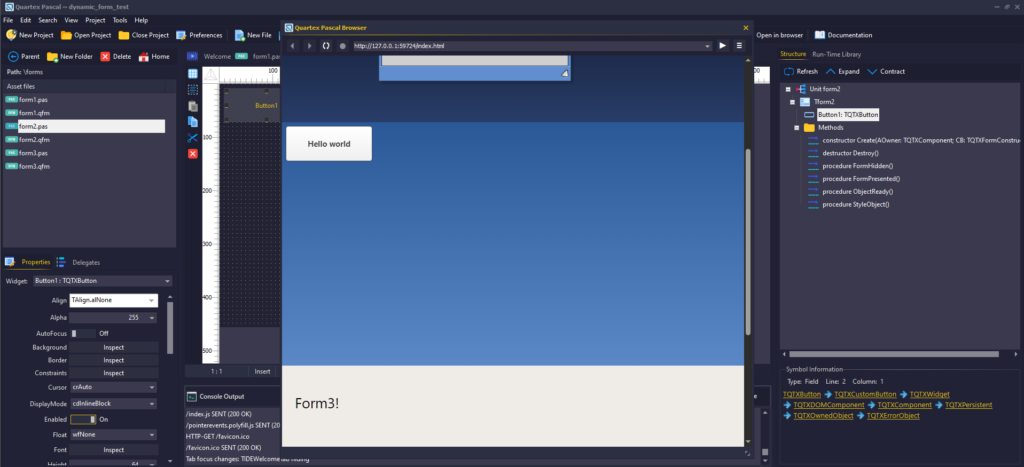
Dynamic application model, showing forms in a stacked, top-down fashion
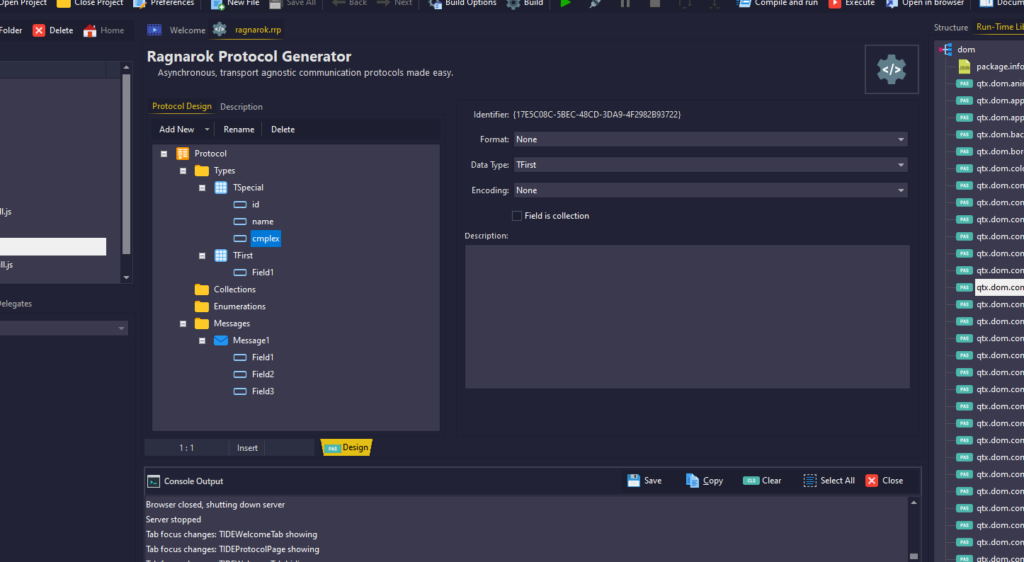
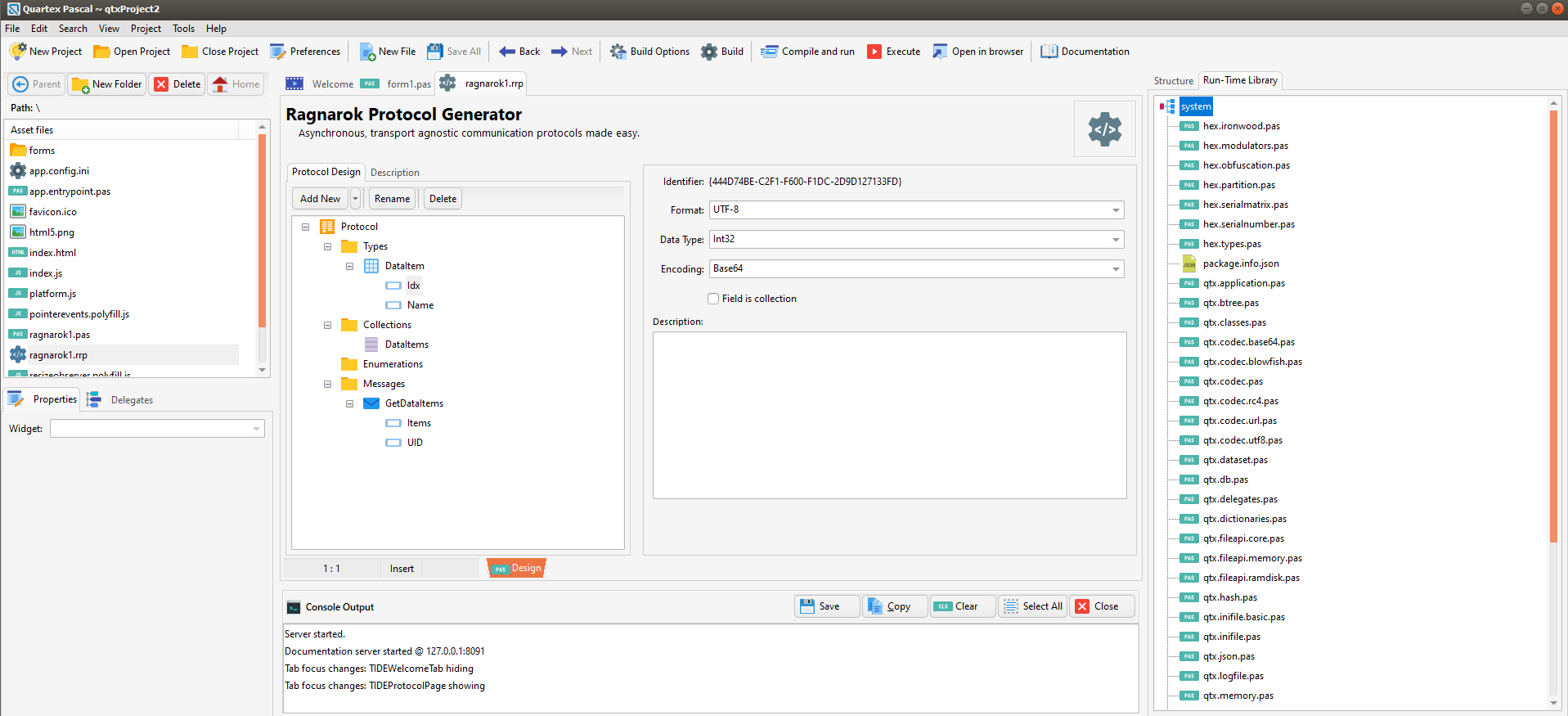
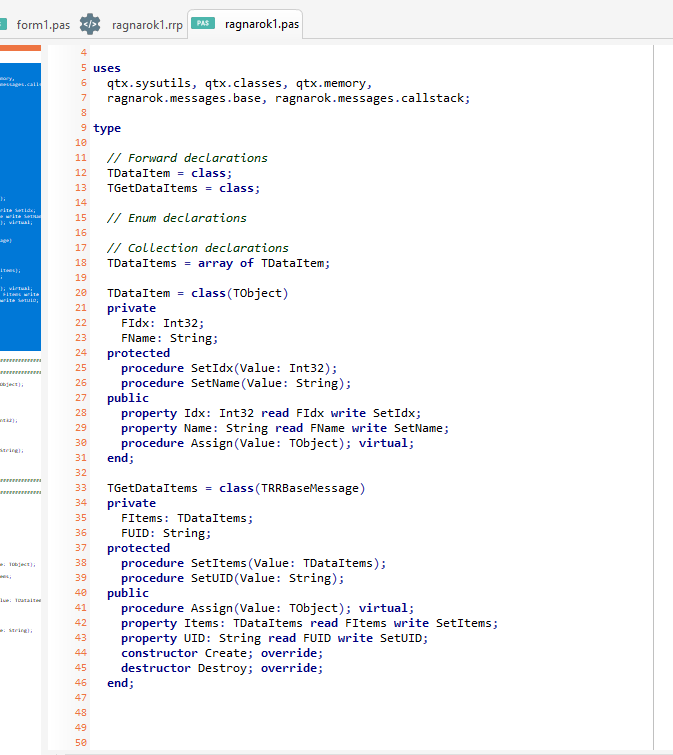
The Ragnarok protocol designer has seen a lot of love since that is central to our back-end development. All protocol objects now derive from TQTXPersistent, which now serializes to JSON. This change also means that every class in the RTL that derives from TQTXPersistent likewise have JSON serialization support. Including TQTXComponent and, further up, TQTXWidget and TQTXForm.
The protocol designer has seen a lot of love lately, and its working just as planned! A huge time saver!
The quality of the generated code has likewise seen a lot of work. Since everything serializes neatly to JSON (including binary fields), shipping data between client and server – or between services or web workers, is redused significantly. In many cases Ragnarok will save you weeks of boilerplate coding.
The quality of the generated ragnarok classes is wastly improved. All parts are fully serializable to JSON and makes it a snap to create client / server applications — it basically generates everything you need to get going.
Can widgets be serialized?
Yes ofcourse. But to avoid the overhead of loading in files at runtime (which is a terrible idea when building mobile apps), we opted to not store design data in form-files (*.dfm files in Delphi or C/C++Builder). Design data is converted into code during compilation and becomes a part of the constructor instead. Just to underline that we have no immediate plans for runtime loading of design files.
But since TQTXPersistent now exposes ReadObject(), WriteObject(), Assign() and various JSON serialization methods – we might return to loading DFM files in the future if we see a use for it. Web is not the same as native code, and adding resource management and async startup criteria (e.g waiting until X number of files is loaded before starting the application) is something we wanted to avoid (and have avoided successfully). But it’s nice to know that it’s there and could be used in future versions.
Misc bits and pieces
Other noteworthy changes is the new color, border and align controls for the inspector, which is visually better than just vanilla combo boxes.
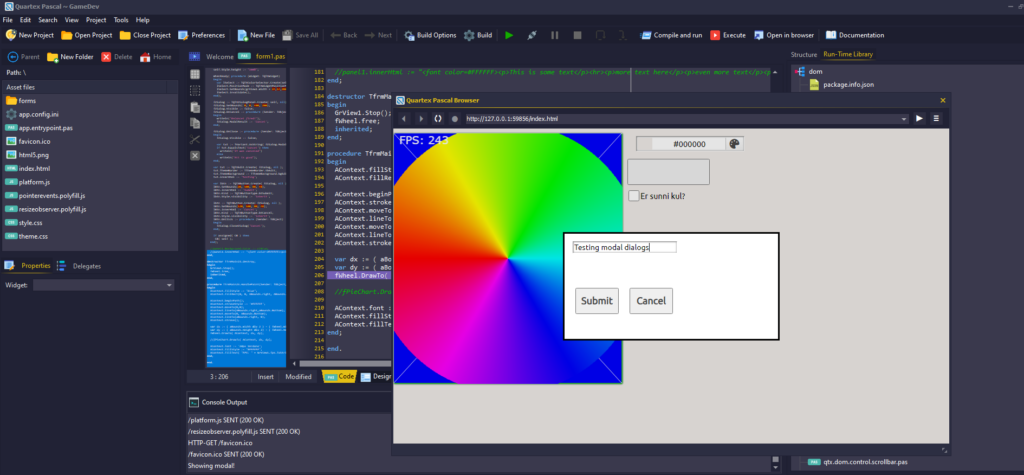
Full support for WebAPI modal dialogs has been implemented
We have also done a complete re-coding of the Align: TAlign layout code, both for the RTL and the IDE, so that behavior is identical. The problems with margin, padding and align priority that some experienced previously – is long gone. And the results are really good!
And last but not least, we now have DWScript running (executing) for both Windows, Linux and MacOS. Both x86 and ARM. Which means that custom property inspectors will be a thing going forward. That means that widget developers can code property inspectors for tighter integration with the IDE. It also means that our own property inspectors will be coded in QTX itself! Meaning that they will be closely knit with the widgets. For example, a nice toolbar designer for TQTXToolbar – so that you can visually add buttons and separators at design time.
We apologize for the wait, but we want to get this done right. Releasing a slapdash product is often worse than waiting a bit longer. I am sure you will agree that it was worth it once we ship it!
This has been a long time coming but it’s finally time for a new backer build! There have been a long list of improvements, so this bould should do wonders – and ofcourse, this version has the long awaited debugger included.
The debugger is a pretty big deal – so we hope you like what we have so far!
Before you download
For some reason Microsoft Onedrive caused a few problems. I am unsure if this is purely on my machines or a general “thing”. The debugger will always create it’s own debug session with the browser, which involves it’s own cache (which it deletes after use, to make sure there are no old files in the cache being used). But if you have Onedrive installed, the “My Documents” path we get back from the OS is mapped to /OneDrive – which cannot be written to. Not even when running the application as administrator.
Until we figure out what that is, the temporary cache is set to a sub-path where the exefile is stored. Which would be “C:\work\QuartexPascal\bin\tempcache\QuartexPascal\Debug\Chromium\UserData\” (phew!). So you wont notice anything really. It was just curious that Onedrive refused to let us create folders – considering it hijacks the OS default path to the user’s home directory.
I even uninstalled OneDrive and rebooted my development machine, but the /onedrive/ path was still returned by Windows. So I suspect Microsoft never imagined that anyone would uninstall the damn thing.
Using the debugger
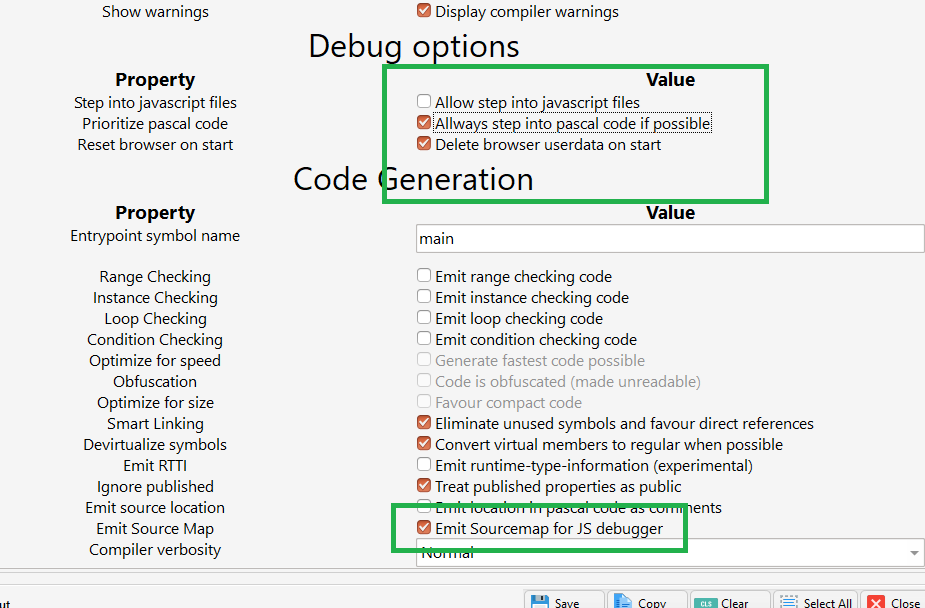
You can make a choice if you want the debugger to jump into the JS (showing you the JS) or if you want to be shielded from the JS as much as possible. The default is to have the “allow step into javascript files” option UN-CHECKED.
While not needed, you can also check the “Emit sourcemap for JS debugger” if you want to use the developer-tools in Chrome directly. If you just want to debug the pascal directly in chrome — just run your code with “open in browser” (you dont need our debugger then), open the developer tools – and off you go. Chrome will then show you pascal code rather than the JS code.
Debugger options
Also note that there is a small delay after you stop the debugger (or close the Chrome / Edge instance) until focus returns to the IDE. Not much, but it’s good to be aware of it. This has to do with the WebSocket termination when closing the debug protocol session.
What I did notice at one point was, that when i closed the browser and immediately started a new session – the debugger was unable to attach to the process (it was still shutting down from the previous session). We are talking seconds here, so just want to mention it in case your breakpoints go out of sync. Just stop the debugger – wait for a couple of seconds, then run it again.
Download
The download link has been published at the ordinary place — so download & enjoy!
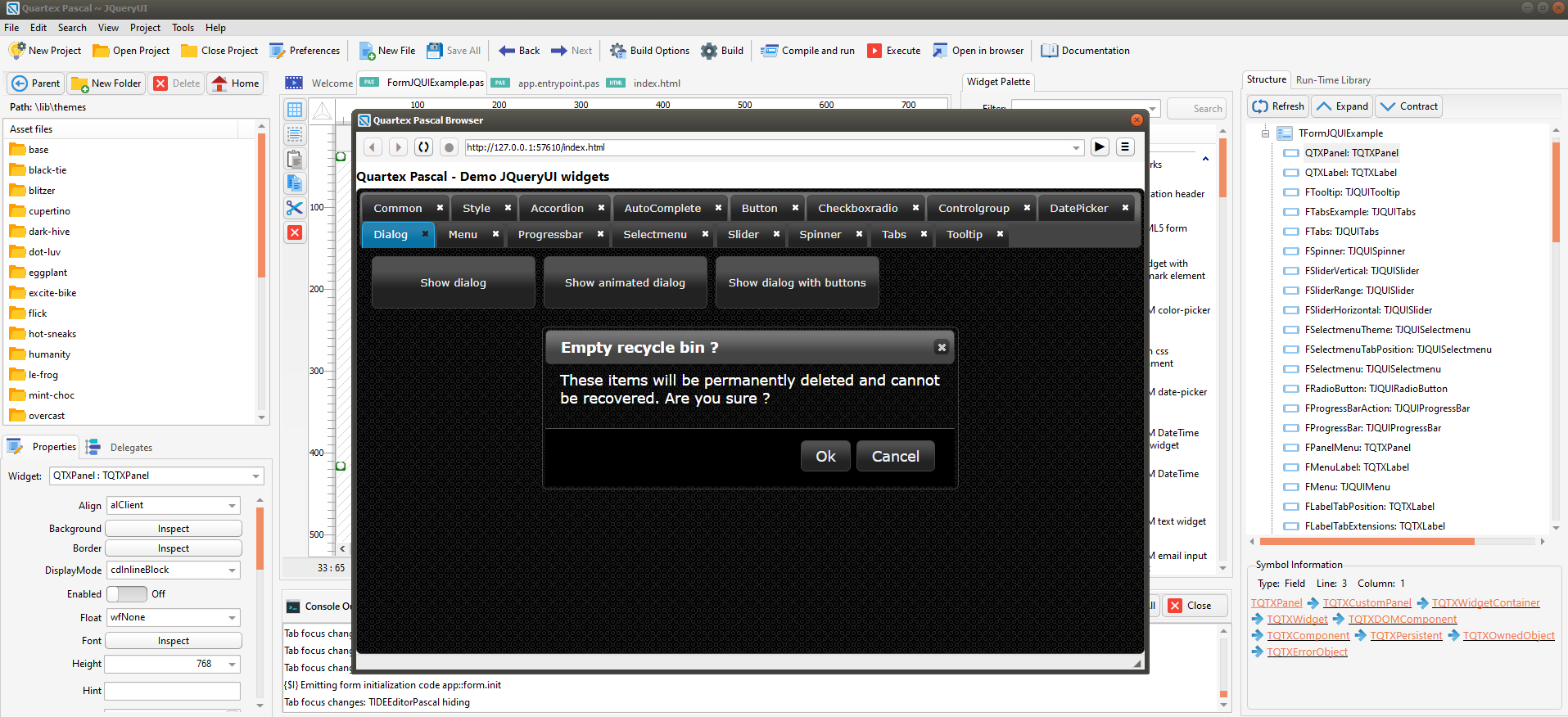
Our master craftsman Ed Van Der Mark just shipped an updated package for jQueryUI. We are so happy to have Ed in our community, and he has implemented some of the most complex JS packages we have. Where others are afraid to venture, Ed seem to enjoy luch – knocking it out of the park again and again!
JQuery and jQueryUI
You have probably heard about jQuery over the years in relation with webpages and JavaScript coding. In short, jQuery is a small library that simplifies common but complex chores in the browser. Over the years jQuery has almost become a standard amoungst web developers, and they simply just expect it to be there as a dependency.
Being able to create jQueryUI specific applications in QTX is a cool feature!
With the success of jQuery (which is a non-visual library) it did not take long before a visual library emerged from the same author, namely jQueryUI. As the name implies this library deals with the user-interface of websites, providing the same simple and unified approach to generating forms, tabs, lists, dialogs — basically all the standard UI elements you would expect.
It simplifies UI creation, styling (themes) and much, much more.
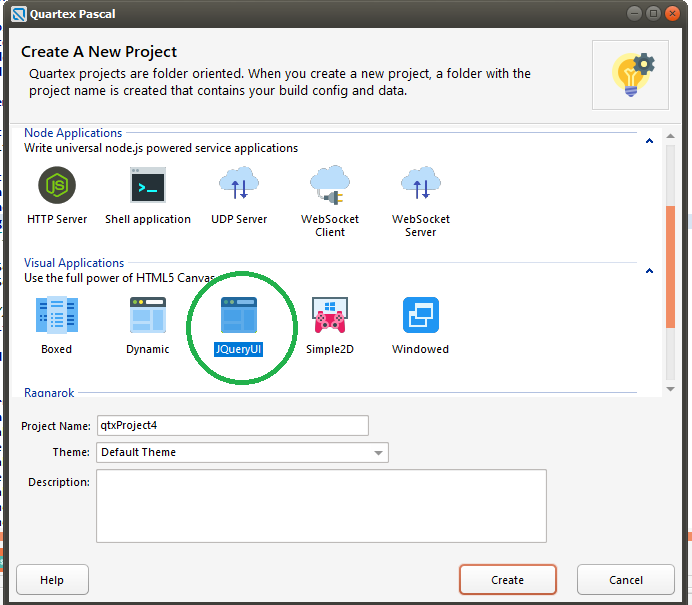
New project type
One of the cool features of Quartex Pascal is that you can extend it with your own project templates. So if you have written some widgets that require specific startup code (in this case, loading the jQueryUI javascript files), it’s always a good thing to create a project template to help people get started. In the updated version of jQueryUI for Quartex Pascal, you will find a new project type that does exactly this.
Ed has added a jQueryUI project type, making it a snap to get started
In most cases the startup code that is unique, tends to be the Javascript library itself. This must be defined in the HTML file (in the header). Visual frameworks likewise tends to ship with a CSS file too.
So technically, you can just copy those lines into your own project if you dont want to start a new one. Also make sure to copy the folders / files that belongs to the jQueryUI framework. The jQueryUI project type is there to help you get started.
In most cases the “project type” doesnt involve anything elaborate, it just makes sure the JS, CSS and other dependencies are loaded before your code is executed
Themes and looks
jQueryUI comes with an impressive number of themes
JQueryUI has it’s own theme system which is not compatible with ours. But the neat thing about CSS is that – as long as the names differ, there is no problem having separate theming schemes co-existing in the same applications. Theming in Quartex Pascal is not a huge, elaborate piece of code like it is under Delphi or Lazarus – but rather a clever and delicate naming scheme.
All QTX widgets (those that are a part of our RTL) all have matching CSS styles, meaning that — if your widget is called TQTXMyWidget, then the theme-file will contain a CSS style called “.TQTXMyWidget”. So there is a natural 1:1 mapping of widget type and CSS style.
JQueryUI does things differently, but again – this does not collide with our system, so you can safely use jQueryUI widgets and QTX widgets side by side.
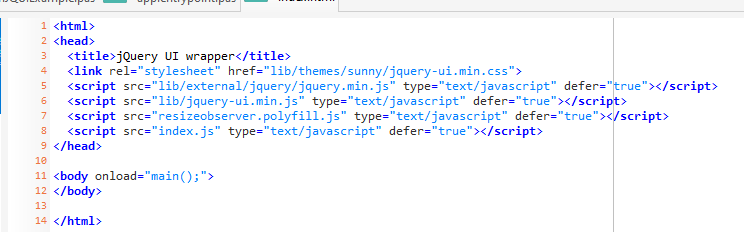
Changing the UI theme is more or less a “one liner” in jQueryUI
If you look closely at the HTML for the project, notice that the first line (link rel) loads in a css file from the /lib/themes/sunny folder. This means the theme will default to that. But you can just load a different theme at runtime (which you also can do with QTX by the way) – or just modify which theme folder you load from.
Why jQueryUI?
If you are wondering why you should use jQueryUI, all I can say is that it greatly depends on what you want to achieve. jQueryUI remains popular within the JS world because it streamlines how UI’s are managed. Since it uses the same coding style that jQuery (the non-visual framework) does, the benefits are probably more obvious for Javascript developers than QTX developers.
I know that jQueryUI is popular for mobile application development. The visual controls are all written to scale depending on the device type and orientation (something we have also taken height for in QTX, thats why the Resize() method has an Orientation parameter). There is a plethora of themes available for it online – so i suppose it provides a shortcut to making your web-based JS application look “native” on Android and iOS.
If your company or customer already use jQueryUI as their primary framework, being able to integrate better with your Quartex Pascal application is a benefit. This is one of the core points of Quartex Pascal, namely that the RTL should be flexible enough to absorb third party JS libraries – and also to co-exist with other frameworks on a website without namespace collision and “taking over”.
And yes, it has some very cool widgets that we lack. We will catch up with these soon enough, and QTX has a depth that most JS frameworks lack — but being able to use the best of both worlds is what we wanted — so here it is!
Other
I have updated more or less all packages. There are a couple from RT that needs attention, but once that is done — a new build will be issues for backers. The debug functionality is awesome, so this will be one hell of an update guys!
It’s been a little while since we posted a news item, since most of the daily updates and posts is happening on Discord for the backers. As soon as v1.0 is out the door that will change, and the first port of call will be our forums here on this website.
Quartex Pascal IDE is now literally just two tickets away from being completed
So what is new? Well, quite a lot! Here is a rundown of the major changes and additions. There are literally hundreds of commits since our last public post, but these are the big ones (!)
Back and Next navigation buttons
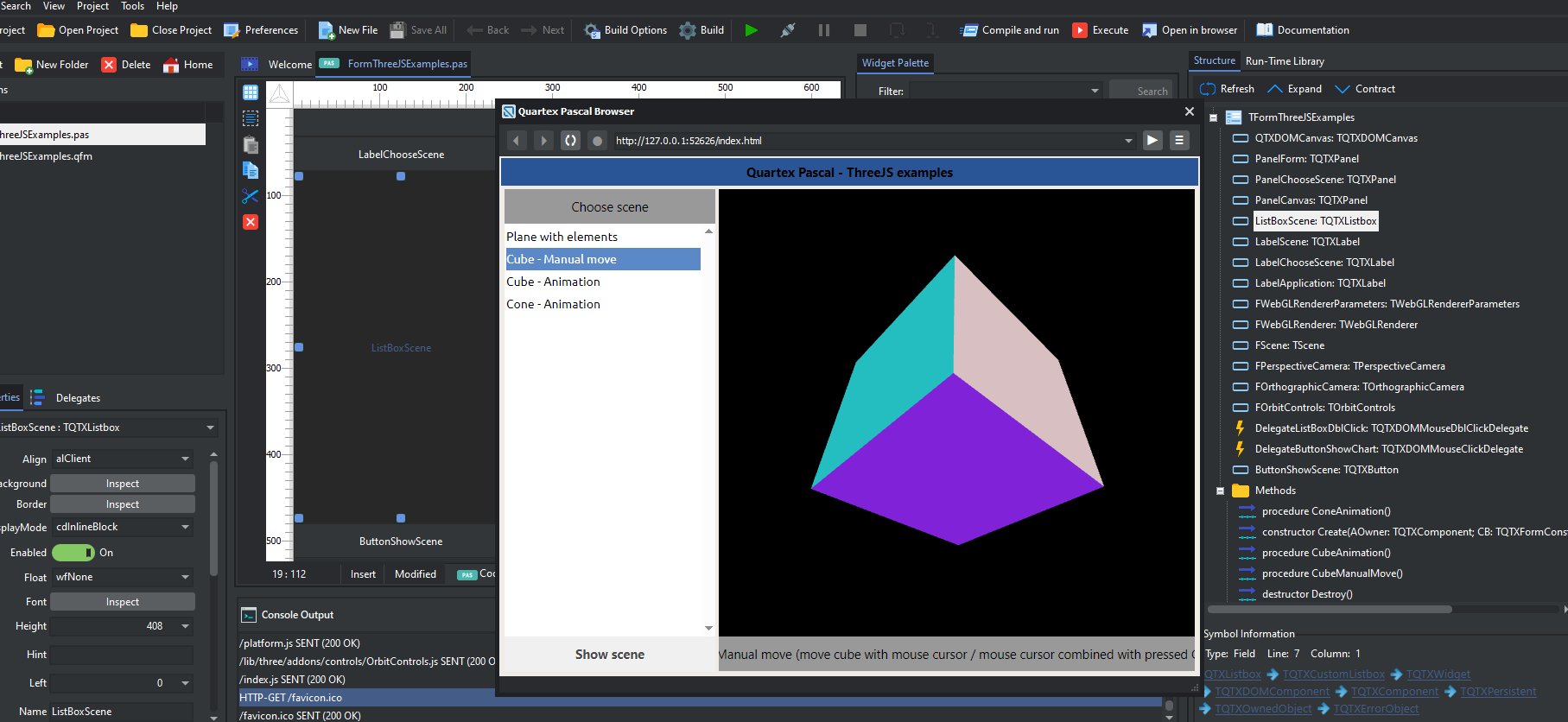
Three.js package
IDE shortcuts and class completion
New unit parser
New Javascript parser
Debugger has been added
Remote debugging
Ragnarok bugfixes
Mount any path as a file-source
Back and Next navigation
This is not really a huge feature, but being able to click the back button to navigate to whatever unit and location you visited previously, and forward in the same fashion, is a very handy feature to have.
Not too exciting but man, you miss it when it’s not there !
It is more or less standard in both Lazarus and Delphi IDE’s, and it’s something that people are used to.
IDE shortcuts and class completion
Again, nothing super advanced – but supporting the most common keyboard shortcuts – both in the form designer and code editor, that Delphi and Lazarus supports is a must. This includes class completion.
Three.js package
Ed van der mark has implemented a full wrapper for three.js, which is by now the de-facto 3d library for HTML5.
The Three.js library is massive, and Ed has implemented more or less everything so that it can be used as Object Pascal classes
This means that you can implement some interesting 3D projects in QTX, or roll your own widgets that renders 3D scenery. This is a HUGE framework and Ed has done a spectacular job as always!
New unit parser
This one is more elaborate and is basically our own parsing framework. The reason we implemented this, was to avoid having to do a full compile in order to navigate code through the AST (abstract symbol table). This affects features such as renaming a unit, renaming a class, adding a unit to the uses list, extracting defined units in the uses clause, checking if methods exists for a class definition – and many other functions.
New Javascript parser
This was a huge task. Basically we have upgraded from Besen-1 to Besen-2, which means that the IDE is capable of handling the latest JS files. So when you open a JS file, the IDE will quickly parse and list the symbols much in the same way as it does for pascal.
New Javascript parser that handles the latest JS, including modules and expression isolation
We will later use this for code suggestion, so that working directly with JS files will be as simple and elegant as possible.
Debugger has been added
This was a monumental task, but it’s one of those things that — once you started using it, you simply cannot live without it. And yes, this is a real debugger. This means we had to implement the full might of the JSVM debug protocol (which is massive), and do live symbol translation in real-time back to object pascal (!)
So you can now set breakpoints, step through the code, hover mouse over symbols to inspect their values — and everything you are used to doing in Delphi or Lazarus. I have yet to see a feature like this outside of Visual Studio for Webassembly, so it’s a pretty big deal. It lifts the product up to a whole different level.
And if that was not enough, the debugger also works with server runtimes. That means you can now debug your node.js servers (!)
Supported runtimes are:
Chrome and Edge (windows)
Chromium browser (Linux, MacOS, Windows)
Node.js
Bun
Deno
There are around 8 alternatives to node.js out there, and while we have not tested them all – if they support the Chrome debug protocol, then it will work just fine. Providing that they havent done anything weird in their implementation obviously.
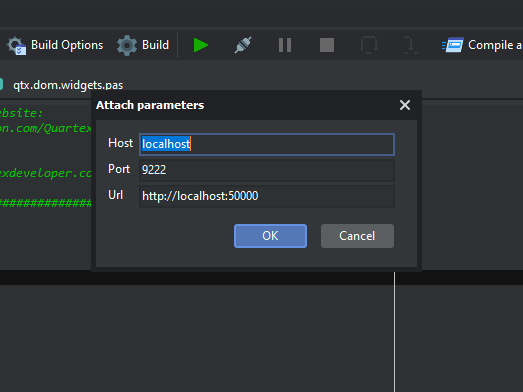
Remote debugging
If being able to debug both running browser code and node.js code on your machine was not enough, we have also added support for remote debugging (!)
This means that you can deploy your node.js server to a secondary machine, be it a different machine on your own network, in the cloud, or perhaps a Raspberry PI you have floating around the place — and then connect to that from your development machine and debug it.
Attaching to running processes on a different host is now possible. Note: This dialog window is just temporary, a more descriptive and easier to use form will be added
This is especially handy if you are working on embedded projects or IoT projects, using SBC’s (single board computers) which are headless (no visual output, just a server for example). Being able to attach directly to your running node/bun/deno process over the network, set breakpoints, inspect values etc — is a godsend in complex ecosystems.
Ragnarok bugfixes
A couple of minor hiccups had found it’s way into the Ragnarok protocol designer. These have now been fixed. So you can now use Ragnarok in your projects to generate message classes. These classes serialize to and from JSON and are designed to be sent between client and server (or any endpoints). Ragnarok is also used between the main website and any running workers, and also between IFrame’s and the main website.
Ragnarok files can be added to any project. The compiler recognize them and generates ready to use code that you can use in your client / server software
It might not seem like a big deal right now, but once you start writing complex micro-services that cross communicate, you will love it. It also plays a key part in our Database infrastructure.
Ragnarok generates message and datatype code for you, based on your protocol definition files
Mount any path as a file-source
The IDE is created to be oblivious to where files actually reside, and works completely with a concept of “file sources”. A filesource provides more or less the same functionality as a normal disk-drive, except that it can be a package (zip file), a local folder, a network share, an ftp connection, a dropbox folder — as long as we have a filesource class for it, the IDE can use it.
When the IDE starts up, it mounts the RTL packages – so that the RTL units become available to it. Secondly, it will attempt to mount any *.PKG files in the packages folder. When you open a project (which is a folder, much like Visual Studio operates with), a filesource is created for that too – and is added to the internal list.
Adding file-sources is now very easy in the preferences window
While this solves how the IDE handles projects and packages (be they local or remote), there is something to be said about re-using units. In Delphi or Lazarus you would just add a path to the search-path-list.
In the preferences tab you can now add as many paths as you like, and the IDE will mount these as file-sources. This works exactly like a search path, so there really is no difference. Since it treats these paths the exact same way as a package is treated, you can in fact have units that register widgets with the component palette in there, as well as package information (technically a “folder package”).
This is very useful when you are developing a package for commercial sale (a sealed package), because when everything works as expected – you can just zip it down and rename it to PKG (open package), and then run the package wizard to convert it into a sealed package with provisioning.
Reflections
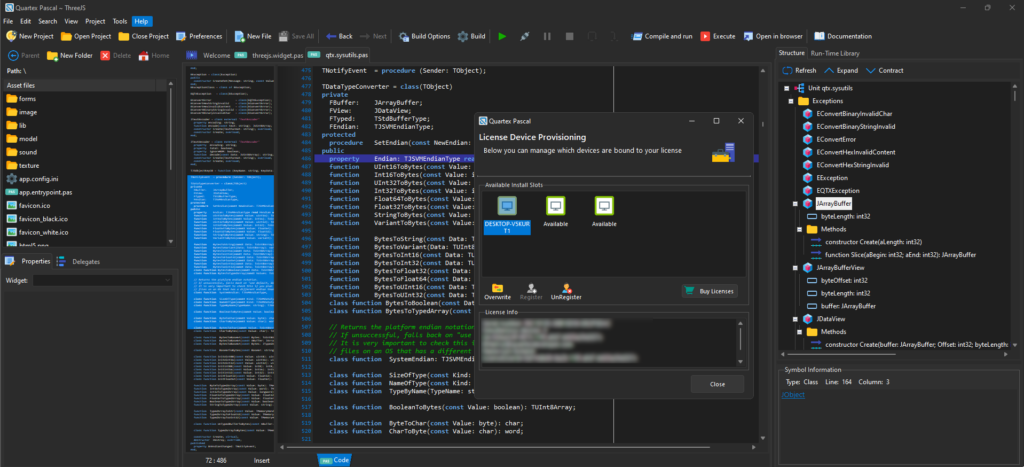
We literally have only two tickets left and the IDE is finished (read: version 1.0 is finished). We will then focus entirely on node.js and implement our back-end servers for license management, provisioning and more. As soon as the license management system is implemented – you can download a trial version and enjoy the fruits of five long years of continous development.
QTX literally is the “delphi for the web” that people have wanted for years now, and since we dont have to deal with WinAPI – writing custom controls (a.k.a “widgets”) is much, much easier. It’s even fun! There are so many packages that can be written, and there will be a kick-ass package manager where you can download, install, buy, sell and do everything you need with third party packages.
You will probably create some cool visual controls yourself and upload them for sale, which for crafty developers can be a nice source of passive income.
This has been a long time coming, but since it requires no more than a day’s work under our new codebase, I figured I could add it as a surprise. QTX now supports a library project type!
What do you mean, libraries?
While the IDE focuses on visual client projects (browser) and non-visual server projects (node|deno), some of our backers have voiced that it would be really useful to have a more 1:1 approach to Javascript.
The IDE now sports a new project type, namely library. We will no doubt expand on that type in future versions
Typically these backers work with JavaScript daily, either maintaining existing websites, or having to write JS for new projects. While we can all agree that JS is indeed powerful in the right hands — it is not very productive. Just from a time perspective (the time it takes you to implement something) Object Pascal is without a doubt more productive.
For them, being able to write code that doesnt pull in the whole might of the QTX runtime library is a productivity boost.
How does a library look like?
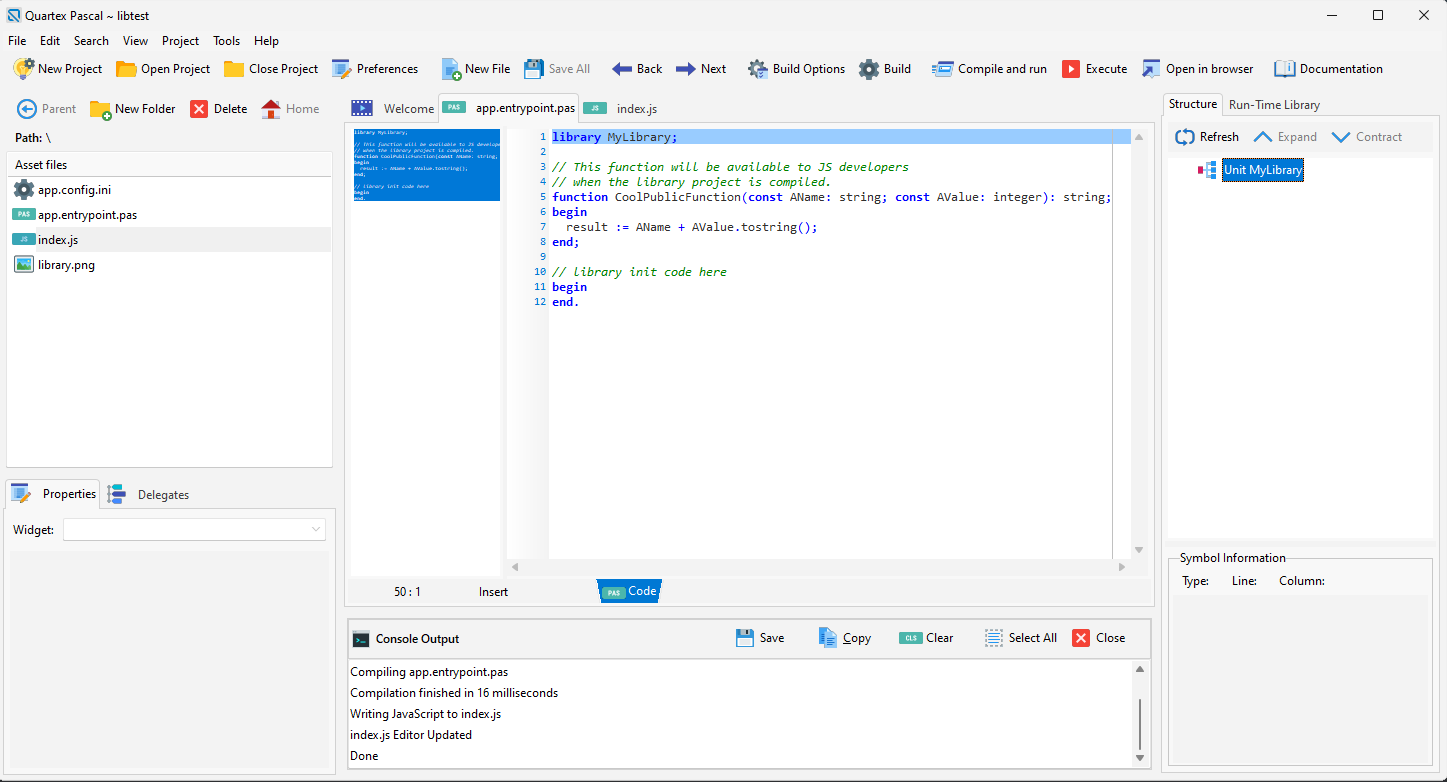
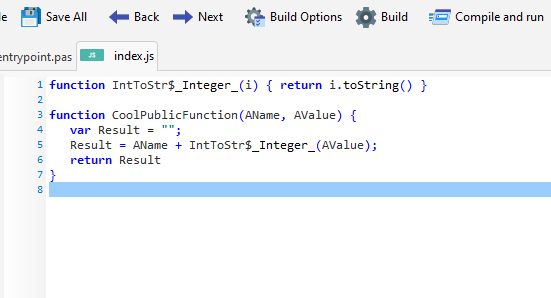
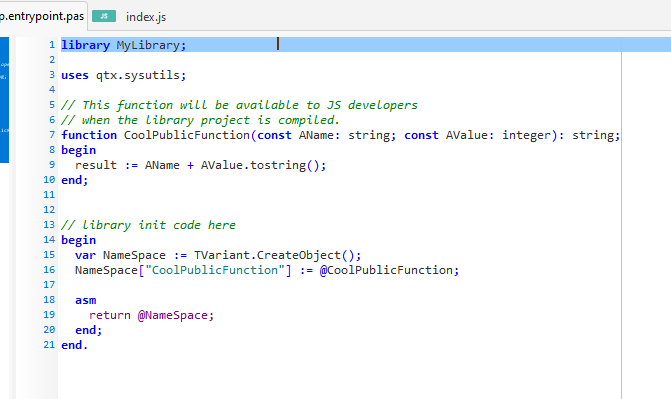
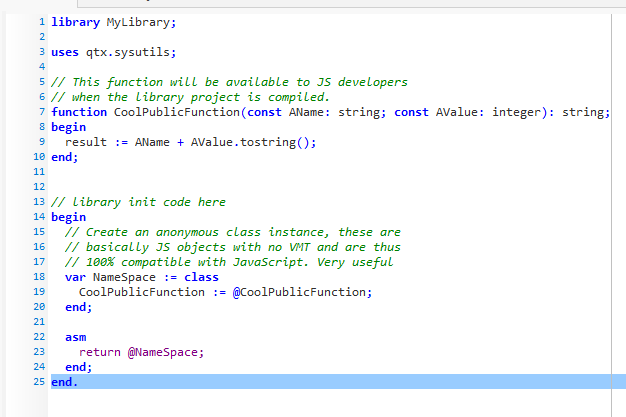
If you have ever written a DLL library with Delphi or Freepascal, you already know what a library unit looks like. It has the same structure as a program unit except that it starts with the “library” keyword. Here is a clean cut library example which contains a single function:
Since QTX contains a full compiler you need to make sure you dont apply symbol obfuscation in the project options, or the names of your functions and procedures will be garbled. But when we compile the above we get the following code:
If you omit using the begin/end. initialization block, it is also omitted from the output, leaving just clean functions
In other words, a library emits a javascript file that you can work with in JavaScript projects, and that other JavaScript developers can make use of. And just like a native DLL you need to make sure the functions and procedure names are valid. I suggest you prefix them with a unique combo (just like we use QTX as a class prefix in the RTL) to avoid confusion or namespace poisioning.
Following the rules
A lot has happened in the world of JavaScript these past 10 years, so you might want to post-process the library code a bit before you shart sharing it. I mentioned namespace poisioning in the above paragraph, and that is very important to avoid. Basically that means, that if you simply load in the generated javascript file – you risk overlapping with existing Javascript functions with the same name.
It is also slightly bad taste to define your functions in global scope, you probably want to isolate your code inside an enclosure, like this:
var _myLibrary = (
function setup() {
// Library code here
})();
What Javascript developers typically do, is that they return an object (also called a namespace object) in the above function, which only exposes the functions you decide as named members. So something like this:
var __mylibrary = (
function Setup() {
var _tmp = {};
function hello() {
return "hello";
}
_tmp["hello"] = hello;
return _tmp;
}
)();
That probably looks very complicated, but it’s really not! Let’s break it down and have a closer look.
The ( and ) characters that we wrap around the “function Setup()” basically tucks away the content as an expression. This means that it’s content is not visible in the global space (which is what we want). The “();” at the end means we execute the expression block. This works because the expression block will resolve to a function.
If you look closer at the actual function, you see that we create an empty object at the beginning of Setup(), and that this object is later returned as the result.
Since this is all wrapped as an expression, that object ultimately bubbles out of the function, and further – out of the expression. This is more or less the same as if you returned an object instance from a Delphi function. The only difference here is that we sculpt that object in it’s entirety inside the function.
Once the object bubbles out of the expression, we store it in the _mylibrary variable. This means that we can only call whatever functions was registered in that object, everything else that those functions might depend on — is neatly isolated inside the expression block and not reachable from public scope.
So if we want to reach the “hello” function in the example code above, we have to call it via the _mylibrary object, like this:
console.log( __mylibrary.hello() );
The moment you null out the __mylibrary variable — the entire library vanishes into the void of the garbage collector.
Creating the namespace object from pascal
You can create that this namespace-object as a part of the pascal startup code if you like (simpler). You still need a bit of post processing (wrapping it as an expression), but it does help simplify things. You can do this for example:
Since there are only functions in JavaScript we can safely add a inline-assembly return call at the end without causing problems. In this case we just dump out the object we just populated, exactly like i outlined earlier in JS code.
Using the RTL units does pull in more code, but you also get more functionality than several JS libraries combined
In this case you would just remove the whole “var main = function” part (and curley brackets), since you are already putting the whole shabam inside the Setup() function. As a bonus — with such a namespace object you can use obfuscation. The compiler will automatically map the obfuscated symbols. So “CoolPublicFunction” will still be called that in the returning object — even though it might be called something else entirely inside the expression block.
An alternative way which doesnt involve creating an empty JS object, is to use anonymous classes. Anonymous classes makes it a lot easier when you suddenly want to add some structures to the object, like version info or something more elaborate. Remember that these classes are not pascal classes, they are “in place sculpted JS objects”:
More fancy-pants syntax wise, but with an elegant output
The output of using an anonymous class is:
var main = function() {
NameSpace = {
"CoolPublicFunction" : CoolPublicFunction
};
return NameSpace;
}
All things considered, libraries via QTX represents a significant time saver. Having to add maybe 5-6 lines in post processing – is nothing compared to the amount of time you save by using pascal.
Creating a global object
JavaScript developers have for the most part moved away from putting everything and it’s grandmother in global scope, but between you and me – in 99% of the cases it makes no difference. Stock JS libraries like jQuery registers as a global object, as does more or less all the major libraries.
I am not advocating that you stuff everything in global space (e.g application critical data). But for libraries that are meant to be used by your whole website the criteria is different.
Making the library globally available simply means registering it with the window object, like this:
window["mylib"] = __mylibrary;
Once registered there, you can access it from anywhere as “mylib”. As you probably understand, with the sheer number of libraries out there this can potentially lead to overlaps and conflicts. I cannot stress enough how important it is to prefix your names with a combination that uniquely identifies you particular code.
Cherrypicking from the RTL
The moment you start referencing the RTL in your library code, the complexity of the generated output increses. Use of TObject will bring in VMT typing, sprintf and a lot more. Fundamental units such as qtx.sysutils.pas depends heavily on lookup tables, so immediately you see a bump in the footprint. Both in initialization code and the included methods.
qtx.sysutils.pas pulls in around 1200 lines of code. But keep in mind that this is memory handling, streams, text codecs and a complex datatype encoding that makes QTX so incredibly powerful to begin with. It’s important to pick your battles.
Having said that, it is still mince-meat compared to what other compilers are spitting out. The QTX RTL is optimized for speed and some of the functions in the RTL are actually libraries in their own right in the JS world. The memory buffer management, streams and datatype conversion (moving between untyped memory and typed datatypes) that we take for granted in QTX, simply do not exist in the JavaScript reality. This is why QTX can do stuff out of the box that would take JS developers days and weeks to accomplish.
As always is the case with object pascal, the RTL usually adds some initial size to your output — but once added, the rest of the code that uses the RTL is typically very small and fast. This is philosophical debate more than it is technical. Object Pascal is a language of practicality. We favor safety and completeness more than we do codesize. I agree that the code elimination process could be better and more agressive, but it ultimately boils down to inter-dependencies in the RTL (of functions using existing functions, thus both have to be included in the output).
Either way, you can cherry pick all you want from the RTL, and compared to what vanilla JS developers have to work with – you can ramp up functionality quickly and efficiently.
In the future we might put more work into doing some of the registrations for you, like wrapping the code as an expression, using attributes to mark functions for export and so on — but right now, low level is what people have asked for. So that is what we provide.
We are nearing the end of this developer cycle, meaning that the last deep-dive is coming to an end, and thus we turn back from the low-level coding and return to the UI tickets and final push.
Would you believe that the entire IDE uses between 50 and 70 megabytes of memory? It’s absurdly lightweight in this day and age, and very very responsive now that we have done some hardcore optimization.
There have been a few hiccups along the way, but nothing we cant handle.
Unit structure and AST rebuild
The IDE has a new and very fast parser in place. This parser does not replace DWScript, but is meant to compliment it when doing complex tasks. Our parser is much faster than DWScript since it technically doesnt parse beyond the implementation keyword (so more or less only half the unit, if that).
What our parser excells at is to quickly find out where a piece of text is located. It can be something as simple as the “unit” keyword and accompanying name, to more elaborate tasks like finding a class definition – and further extracting information about a specific property.
The most immediate use is when dragging and dropping widgets onto a form. Here we must quickly check if the unit where the widget is defined is already in the form’s uses list. If it’s not, then it needs to be inserted. Having to literally compile the whole unit during a drag and drop operation is counter productive. So these are some of the tasks where a fast, ad-hoc parser can do miracles.
Those that tested the last update probably noticed that it was faster already, but after these latest changes — it’s virtually instantanious.
Unit structure
What I am doing right now is to make sure the unit structure is rebuilt only when there are changes, and that only the changed nodes are processed. This is not as easy as you might think since so far the unit-structure has been updated whenever we rebuild the model (which the IDE does quite a few places, which is why the new parser will come in handy).
Previously we rebuilt the model “on demand”, so whenever we needed the AST object we basically issued a rebuild on the spot. This works, but as the IDE grows in complexity it is simply not sustainable to have models being spawned left and right. As such I have isolated model rebuild in a separate class, which listens for changes to the current editor (if it’s a Pascal tab) and will schedule a rebuild after a change is finished. So it will know when you start typing, but will wait until you stop typing to issue a rebuild.
The Unit structure manager (called a provider in our system) likewise listens to the same change notifications, and will enter “wait state” when it notices a change. Because it knows the model will be ready as soon as you stop typing.
Ditching Facebook
Facebook have been acting strange lately (again) where it keep classifying articles and content that i cross post as “spam”. How exactly I can spam my own groups with coding links and articles I wrote is beyond me, but I think it’s time we move away from Facebooks.
As such I have invited the members of our Facebook group (the backers of the project) over to Discord, and from now on any news and updates will be first posted to the forum — and then cross posted to Discord. I dont see any other way to deal with this because Facebook is quite frankly unreliable. It’s the same thing that happens again and again, and since I run several groups closely knit by topic — my posting behavior will always be different from whatever they trained their Ai model on.
But it’s not a huge loss. We always did plan to leave Facebook. I had hoped we could use it to finish version 1.0 before we jumped over to our own forums completely, but — might as well do it now and get it over with.
Other additions
The TQTXPixmap class has been getting some much needed love. I have added gradient methods to it, with support for the 5 most common gradient types (including radial).
I likewise added Draw(), DrawStretched() and DrawRotated() methods to it, making it very simple to copy raw pixel data between TQTXPixmap instances. I am using scanline copying as much as possible, so as far as 2D graphics goes this class is now very, very powerful.
I also fixed a problem with the RGBA alpha blending code, and optimized more or less the entire library. This is quite important because this class also works under node.js — which by default has no graphics capacity what so ever. Eventually we can add JPG / PNG and GIF codecs to it, making it 100% runtime independent. I quite fancy compiling a C/C++ font renderer to asm.js too, so we can do live decoding and rendering of TTF font files — but right now this is not a priority.
UI tasks and back-end node.js server
As we now turn the boat and return to land so to speak, we have a relatively small list of UI improvements that needs to be done (including that annoying bug when you rename and/or delete files in the active project folder) — and then the main system is ready.
Before we launch there is just one thing to add, and that is to implement our license server. This will be coded in QTX ofcourse and will handle product registration and trial versions. This is quite crucial but it needs to be in place.
Oh, and I want to add one more project type to the IDE, namely “library”. This will basically be a project type that adds nothing – meaning that it will not inject any startup code. What you write is what you get (more lightweight compilation to JS) which makes it more suitable for doing library code, or code modules that you wish to use from JS. This can be quite handy when you do JS tasks regularly, but would like the benefit of using object pascal and the RTL instead.
This was an interesting case. Kevin, who is a Ninja bughunter and all-round super coder, reported back that he could not for the life of him get the Kepress delegate to work!
He had tried the obvious, like creating the delegate class manually from scratch, forcing it to trigger, giving the delegate various parents to see if that help – but to no avail. Nothing happened. Quite frustrating to say the least when you are creating examples and being a technical writer.
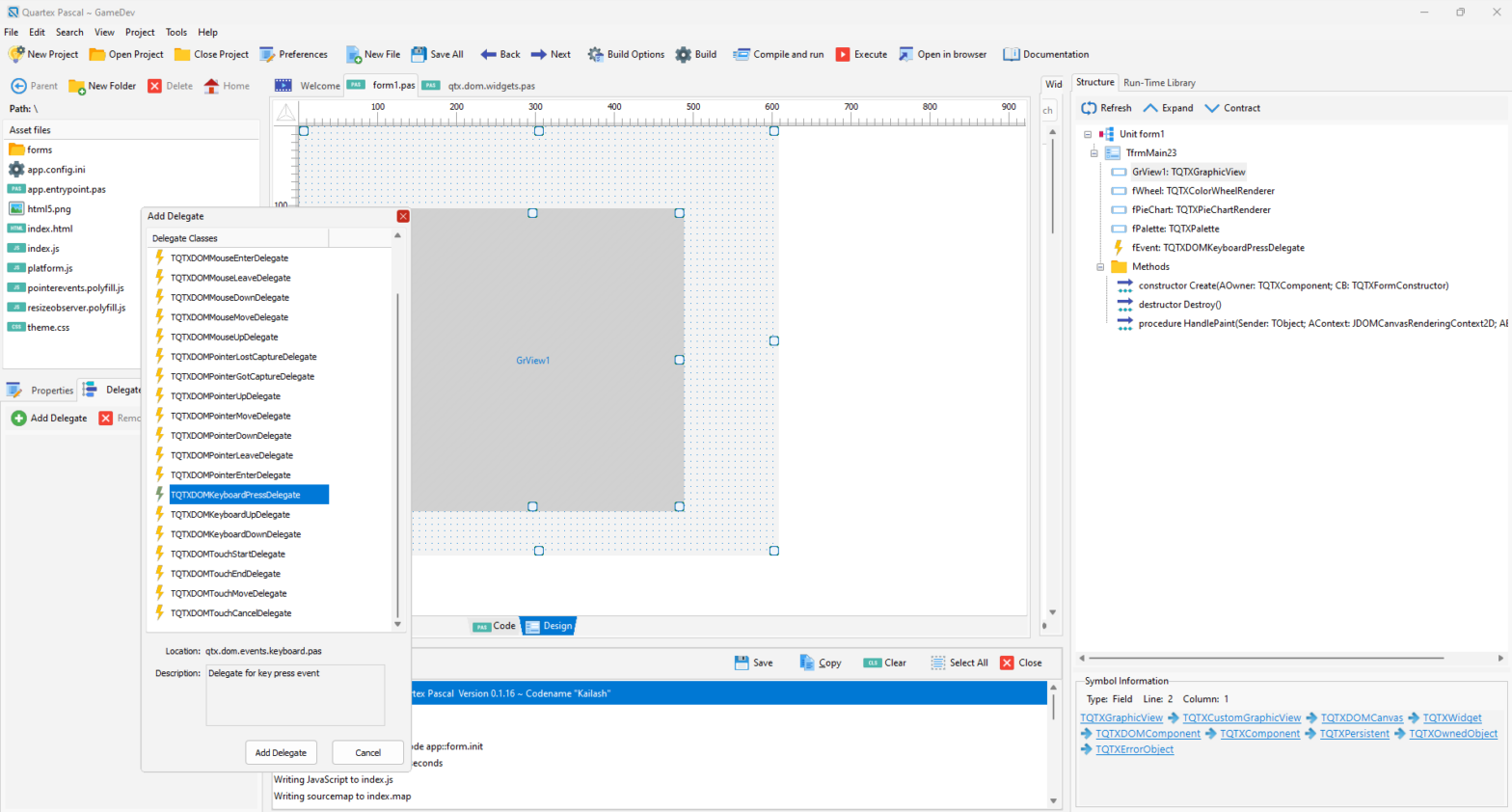
Adding delegates to a widget is simplicity. Just selected a widget, switch to the delegates tab by the inspector, and click Add ..
While working with HTML or Quartex Widgets you have probably noticed that some of them have focus abilities. Like a text edit box, memo field or button. These widgets not only capture the focus, they visually reflect that back to the viewer. Mostly in the form of a changed border or highlighted edit-cursor.
So what makes these widgets so special? And why do they get first dibs at ordinary events?
To focus or not to focus, that is the question
Despite the radical morphing into a multimedia powerhouse, the modern browser remains at heart but a humble document viewer. And in the world of text content, the browser cannot treat all entities equal. Control elements such as buttons, scrollbars, lists, comboboxes. memo fields and the likes are usually “real” widgets. Meaning that they are actual elements created by the underlying operating system (WinAPI, MacOS, Linux to mention the most common).
But, what separates them from pure browser controls, is that they have properties that is rarely accessed.
One of these properties is: tabIndex
As a Delphi, Freepascal or C/C++ developer this property should be no stranger. to you. All visual UI elements in a real, native application has a tabIndex: Int32 property in one form or another. Usually in concert with a tabStop: bool property. So when a user tabs through a form design, the tabIndex says which widget should receive the focus – while tabStop: bool tells the OS if it should skip over a tab item and more to the next.
Why is this even needed you say?
Well, imagine you are making a shopping trolley for your amazing webshop. The customer has ordered 10 amazing products that you display in a common top-down grid. The user tabs through each row just to make sure he ordered the correct amount.
The values you set for tabIndex, determines where in that tabbing-order your widget get’s focus. So in a list of 10 items, if you set your tabIndex to 3, then your widget will get’s focus when the customer has pressed tab 3 times.
There really is nothing more to say about tab order.
QTX Focus and delegates
If we return to Kevin’s case, he had done everything correctly.
He created a KeyPress delegate on the main form, doubled clicked on the delegate in the inspector. This automatically creates the event handler for the delegate. And he went on to implement his code. Except that when he tested it, nothing happened.
Well, it took me a couple of minutes to recognize what this was. It’s been a while since I have been dealing with delegates, so i was baffled myself a while there.
The first thing I did was to move the delegate to the Application.Body object. This is the document itself, and the first element to receive any delegate. All events / delegates bubles upwards in HTML5, so interestingly enough, the elements at the bottom are notified first.
The event fired as it should there, which meant it had to be something else. And that’s when i remembered the tabIndex rule.
In short:
If you want a DIV or any other “non operating system” element to trigger and respond to common events — make sure you set the tabIndex to something higher than -1 (default).
New property added
Sadly, this property was not exposed in our RTL. I probably thought that it was more something that widget creators would need. I was clearly wrong, so I have added it to TQTXWidget, and it will be available in our next update.
In the meantime you can bypass it with a spot of:
// First method
self.Handle.tabIndex := 0;
// Second method
self.Handle["tabIndex"] := 0;
I suggest the first method since it’s more elegant and avoids a lookup in the handle members list. Just remember the prefixing with lowerase and it’s all good.
When writing games or full screen media
If you are writing full-screen games, or games where the keyboard should be operational regardless of what has focus on screen – I strongly urge you to create your delegates manually and attach them to TApplication->Body.
As you can see from the picture right, both TApplication and TQTXBody expose more or less all the common delegate helper methods – so adding a keyboard delegate that is global, is a piece of cake.
If, however, you are writing widgets that are supported to play nicely with other widgets on a form, then never attach to global objects like this. It will only cause problems and confusion for others.
But if your application will be fullscreen, you have full control over the content, then attaching to the document directly is perfectly valid.
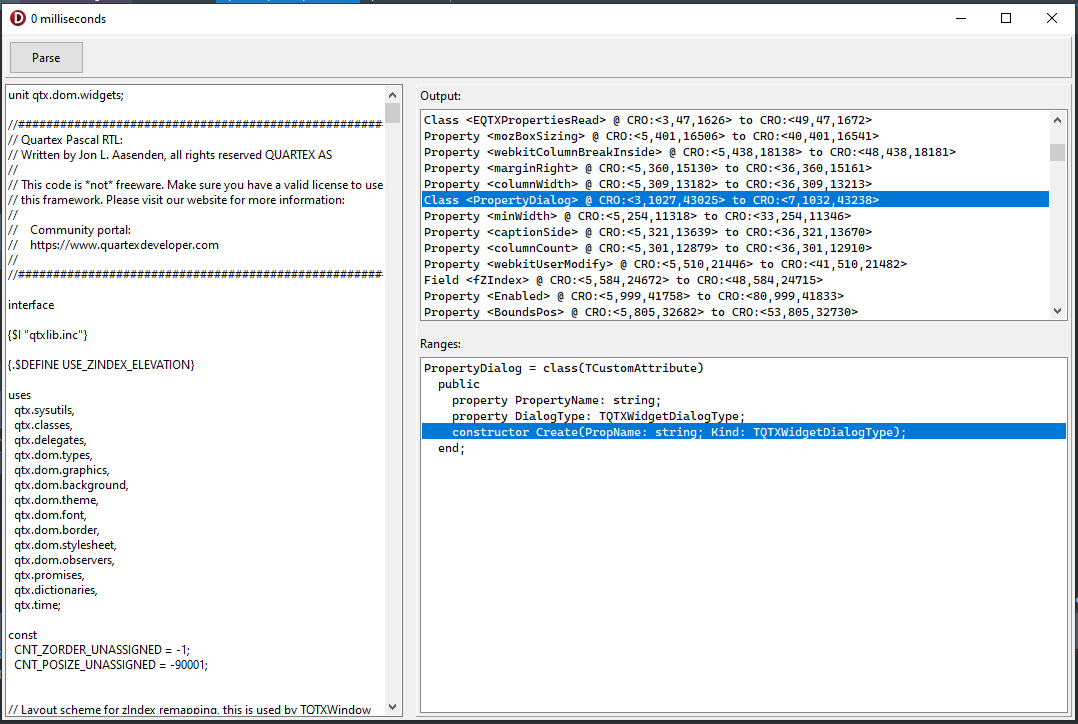
To speed up the amount of time the IDE uses to display the unit structure, we have spent some time implementing a special parser. This parser is diffent from the one already present in the compiler core – in that it does not go through the ordinary compiler steps (tokenizing, parsing, building an AST, structure verification). It is designed to chew trough the syntax according to the language rules, extract symbol names and their positions – and finish the moment it reaches the “implementation” or “end.” termination symbols.
This is also a very hands-on test for the parser framework I wrote about earlier, testing to see how well our framework works with such a daunting task. One thing is having a parser that handles miniscule tasks like an ini-file or dfm text files; a full on language parser is something else entirely.
Performance
Since this is not a full parser in the traditional sense, although it could relatively easily be turned into one, the cost of parsing is surprisingly low. Normally you can draw some statistical vectors between speed and resource consumption, where the latter is usually a penalty of caching and pre-calculation. In our parser there is none of this. It does exactly what it says, and it’s every bit as tricky to implement as you imagine.
The current parser test application. Here parsing qtx.dom.widget.pas from our RTL.
When you write a parser for a language like Object Pascal, especially a living, vibrant dialect such as QTX with it’s many syntax modernizations and enhancements – you really find out just how many combinations and variations the language truly has.
This one for example:
function jsObject: variant; external 'Object' property;
Just like Delphi or Freepascal can reference DLL functions by declaring them as external, so can QTX. The difference is that under QTX we are not mapping DLL library symbols to a local symbol so we can use it; we are telling the compiler what it should replace our mapping with. Whenever we use JsObject() in our code, the compiler will eventually just replace that with “Object”. This is a big difference.
So all we are doing here is telling the compiler that there is an external symbol called “object” that we want mapped as a local function.
The wildcard is that extra keyword at the end, namely “property”.
What does the property keyword do? Well, when the property keyword is found after the external qualifier, then the method will be codegen’ed without parenthesis. If it has parameters, brackets will be used instead of parenthesis.
Another road rarely traveled, is when you have external objects which (just as an example) only allow a write-only property. Take this for example:
Here we have a class that is marked as external, but the JS names for properties doesnt really suit us, so we use our own names in the pascal code. This is perfectly legal as long as we mark the properties as external, and provide a valid name for them.
But notice that last property, FieldRW, and how we suddenly have an external keyword right in the middle of the definition. Basically what this syntax is saying, is that whenever you read from this property — you will just read the JS property called “world”. But you can write to it all you want.
The number of times you will be using these declarations will be slim. And honestly, most people would define these wrapper classes differently. The above will be more useful if you have a JS object that has a “world” property, and then a SetWorld() method. Since these go together in the pascal world you can use the esoteric syntax above to unify things.
My point with all of this was not to scare you with esoteric, edge case syntax — but rather to underline that my parser code have to deal with all of this. I still need to add that somewhat odd use of external, but I think I have implemented the rest of it.
This is why it’s so important to test with real-life units, like those from our RTL that is already being used. Because if it can handle the RTL, then it’s ready for inclusion in the IDE.
Why a separate parser to begin with?
DWS is awesome, but building an AST means doing a full compile of the unit you are editing. If this is a form-unit, it will pull in all the units in the uses-clause (recursively), which however brief is a consuming task. In a perfect world we would just stick to the AST for everything, but reality has proven that it’s sometimes good to have a scalpel and not try to chainsaw our way through everything.
Things like Rename Unit, Add unit to uses, Remove unit from uses, Check if unit is in the uses, check if a class is in the unit, check if a member is defined in a class — stuff that you probably dont think about that the IDE does. We also want to expand things, like rename classes etc too later.
This was yesterday before i optimized things, so it was 16ms slower then 🙂
Once this is in place I will circle back and put our background compiler in a thread, now that a lot of the housekeeping jobs can be delegated to our mini-parser. And then it’s time to deal with the UI tickets and license back-end (yes we need to have the license node.js server on our website before we launch, but just the license stuff, not a full shop!) – and then (unless something else turns up) we are done!