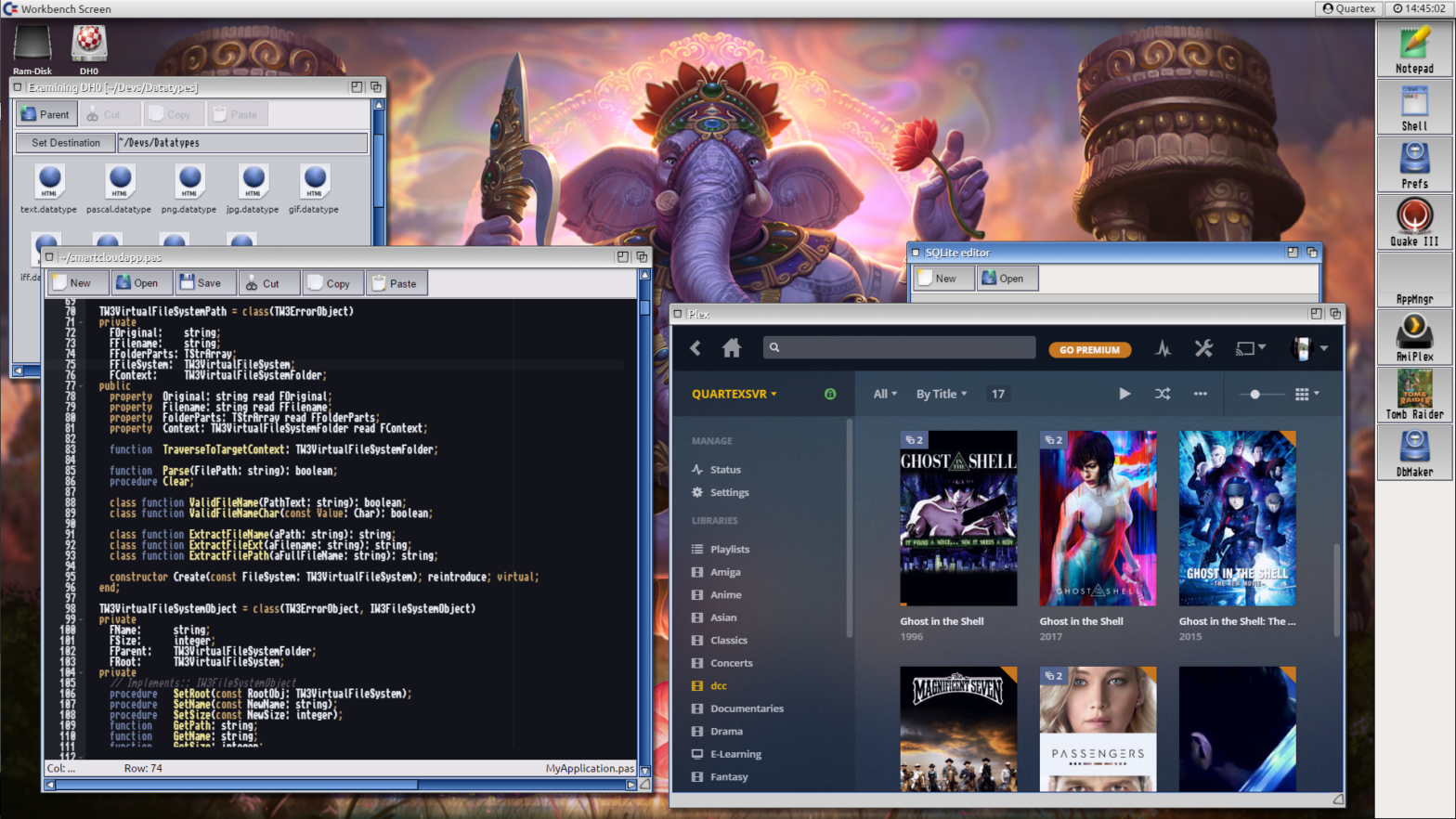
Introduction to Quartex Media Desktop
The concept of ‘Desktop’ is slowly morphing into different things for different users. Technically a desktop is a visual layer that rests on top of a large set of non-visual services that abstracts the hardware, while offering system wide functionality that applications an use to solve tasks. However, a desktop is used differently depending on the platform: you have media desktops, kiosk desktops, NAS desktops (network active storage, usually accessed via the browser) and movie systems like Plex and Kodi. These systems might not always have icons and direct filesystem access, but the visual layer supports application isolation, separate UIs and mouse, pen or touch interactivity.
I began to toy with the idea that if we could implement a desktop using web technology alone, it would in fact be possible to offer the same architecture in a truly platform independent way. If the underlying OS (e.g Linux) was capable of running node.js (a Javascript scripting runtime much like Python) and run a modern browser – a completely abstract desktop and application model could be established. In short: a full desktop in the browser backed by system services also written in portable JavaScript.
Said system could run as a server, be installed as a cloud service, run solo on cheap ARM hardware which boots into a browser in kiosk mode (full screen) or be used as the basis for large scale application deployment. The question was then, which desktop architecture and philosophy would be the best match? After much studying the winner was the now legacy Commodore Amiga OS. A lightweight and highly efficient desktop system that for many defined the 80s and early 90s in Europe.
The reason I wanted to replicate parts of said legacy OS, is because the technology and concepts introduced by Commodore were extremely portable. More importantly the entire system was based on cooperative multitasking which is almost identical to the async event-driven architecture of JavaScript. The Commodore Amiga desktop was decades ahead of its time. Some of the ideas intrinsic to the Amiga desktop were so far ahead that they made little sense in the 80s and 90s due to the severely limited processing power and memory.
In today’s world of IoT devices and cloud centric software however, these ideas make perfect sense.
Why make a web centric desktop?
There are many reasons why building a fully working desktop, complete with filesystem and service layer, is a good idea. The most obvious is that web technology is completely platform agnostic, meaning that it will behave identical regardless of underlying operative system and physical hardware.
Another reason is that despite JavaScript being the most widely adopted programming language today, the browser remains quite poor in terms of infrastructure. Things like process orientation, user accounts and a filesystem over websocket simply does not exist.
There is always the ever changing hardware market to consider. There is x86, ARM and new platforms like Risc-V to consider. ARM is being adopted large-scale by many companies, while Risc-V has usurped parts of the embedded market. To expect Microsoft or Apple to enter these markets quickly is optimistic to say the least. This leaves Linux as the de-facto system for these chipsets – which is a perfect solution for a web centric service layer. Linux deals with the hardware, while the upper layers can be dealt with by web technology.
But the real motivation behind this is ultimately financial. There is a thriving NAS (network active storage) and router market in the world, which currently is dominated by large corporations. Companies like Asustor and Synology both provide a Web based desktop for their hardware which is closed source. Licensing this software in order to create your own NAS systems is not possible, or at least not financially viable unless you represent a company with deep pockets. A single developer for the Synology DM desktop system starts at $3500. And that is before you factor in licensing the right to deploy DM on devices you sell.
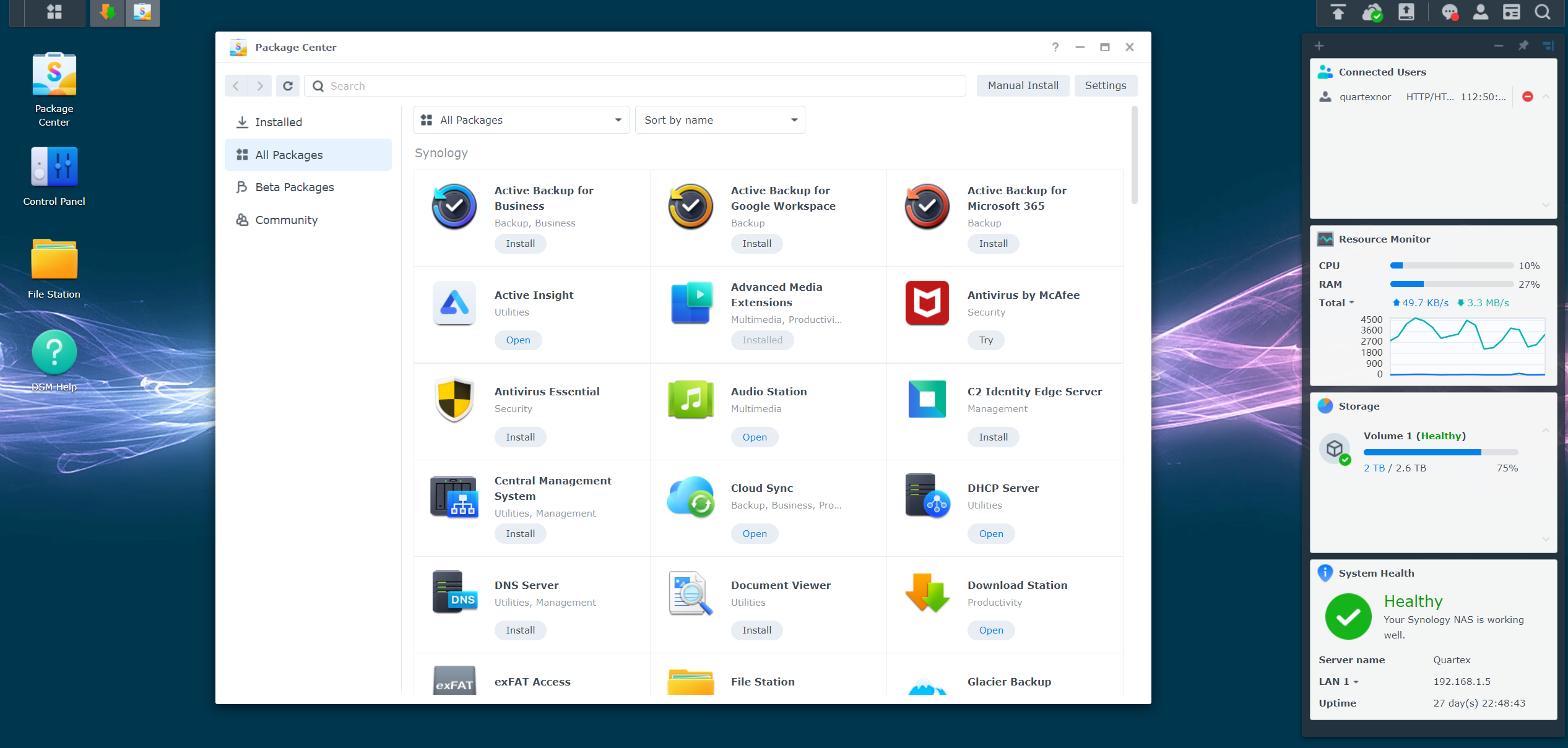
The DM system that both Synology and Asustor is based on is written in a mix of C/C++ and Python running on top of Unix. This means that moving the system from x86 to ARM will not be without it’s challenges. Why they decided to go with Unix rather than Linux is curious, but I am sure they have their reasons.
The more I started to look at what we would need to replicate such a system, the more I realized that node.js would be more than capable of delivering the exact same functionality. As a bonus, once the code ran on node.js, our system would have none of the adaptability issues that often haunt native software when you port it to a new platform.
If implemented correctly, a node.js based system could actually be copied from an x86 based device to an ARM device, with no changes to the code. Obviously preferences files would have to be edited, especially if moving between Linux and Windows, but the node.js backend code would be “universal” in the literal sense of the word.
Cloud centric deployment
If the NAS or Router market holds no interest for you, then consider deployment of enterprise level today. Native software is by nature subject to a whole host of criteria, from low level assembly code – all the way up to use account settings and physical installation on a computer or network.
By building up a complex and rich infrastructure that can be represented in a normal, modern browser – your web applications can be more widely adopted and used, with a much finer grain of control by you, the author and owner of the intellectual property.
Cloud centric deployment eliminates revenue loss, while it opens up for some exciting new business opportunities.
Let us say you implement an invoicing application using Quartex Pascal. How exactly would the customers use this? What are the customers accustom to using? Most people using such software are used to running it on a desktop. Even if they have no programming or technical background, they know how icons work, they understand how forms and windowing works, and they are used to menus, dialog boxes and settings panels.
In short, they are used to a desktop environment.
Cluster architecture
At the start of this document I mentioned the Amiga architecture and Operating System in particular. To give an example of why Amiga OS and its inspiration plays such a central role, we don’t need to look further than the clustered nature of Quartex Media Desktop.

Cluster computing is a topic that has for the most part been reserved advanced developers, if not computer scientists. The benefits of clustering is self-evident, using the combined CPU power of several computers to get results quicker. Due to the complexities involved though, cluster computing outside a lab, university or company is quite rare. And there are reasons for that.
One of the reasons cluster computing is rare, has to do with writing software for it, and working with a program model that can span multiple computers. The whole idea of clustering is not just starting programs on multiple machines in typical Kubernetes style – it is also about spreading the payload of a single program over a group of machines.
From a software development point of view, clustering (in the hardware sense of the word) demands that 4 central challenges have been met:
- Networking: The machines must find each other and automatically register resources (zero configuration) with a master service.
- Dispatching: A unified message protocol that can be applied everywhere, from sockets to message channels in the browser. This way messages flow with little effort through the entire cluster, with no risk of being delivered to the wrong instance or recipient.
- Orchestration: A clustered program consists of at least two parts, simply called back-end and front-end.
- The back-end is a non visual service application that is spawned when the program is started.
- The front-end is a visual program loaded inside a form (window), which immediately opens a communication channel to it’s back-end instance. This is how NAS systems solves running web based desktop programs with live feedback. For example, bittorrent clients that display real-time download progress. Nothing is really happening on the HTML5 layer.
The Amiga Operating System introduced the notion of IPC (inter process communication) as early as the 1980s. A feature that at the time was only available in high-end Unix workstations at universities or research facilities. The way the Amiga solved this was through REXX ports. REXX being a scripting and automation language (read: standard) that enabled users to invoke functions inside different programs, building up complex behavior through automation.
The way this works is that a program registers a set of commands by calling an OS level function. These commands become attached to the program and can be invoked via the applications REXX interface, almost like how a code library (.dll, .so, .dylib) exposes symbols and named resources. These methods can then be called on in a variety of ways:
- From your own programs via the native API
- From a shell script or the AREXX runtime ( Rexxmast )
- From an AREXX script
- From within a document (AmigaDoc, a precursor to HTML and RTF combined)
The consequence of this program model and ways of reusing functionality, was that programs had more value than what was visually represented. It would take competing systems, such as Mac OS, a whole decade to catch up with this way of thinking (Apple Automator).
The difference between Automator and how the Amiga did things, was that the exposed functionality was easier to work with for both developer and user. It was more intuitive, easier to implement for developers, easier to use for non-developers, and exceptionally well planned and integrated.
What is unique about Amiga OS, is that the philosophy and mechanisms involved here, scale upwards. You can take the exact same approach and apply it to System Services, and further to Web Services. Suddenly you have a unified methodology than spans from individual programs, to large-scale cloud services like Amazon or Microsoft Azure. A unified way of working building up complex behavior.
By basing the desktop architecture on said philosophy, Quartex Media Desktop simplifies cluster computing immensely. There is obviously more to clustering than just this, but the importance of a solid foundation cannot be emphasized enough.
- The desktop is not a mock or fake desktop. Behind the visual UI you have several micro-services that deals with authentication, storage (filesystem), communication and more importantly – virtualization. As such the desktop primary goal is to provide an infrastructure for large-scale application deployment. Or perhaps better phrased: to do for JavaScript what Microsoft Windows did for native programs.
- The desktop system also have several sub goals which are specific to its adoption by the community. First and foremost virtualization and emulation; Making it possible to execute and work with native programs directly in the browser; Changing the way we look at machine code into something like bytecodes (which is how Java and .Net operate).
If you have zero interest in cluster computing, that is fine. Embedded development and software deployment like this is not for everyone. The best way to look at this if you have no ambition to provide NAS software or offer your services to Router makers (which is a billion dollar industry world wide I might add), then simply think of the desktop system as a way to publish your applications.
If you write a windowed application in Quartex Pascal, you can either publish that “as is” to a normal HTTP server. Alternatively you can write your own node.js HTTP server if that tickles your fancy — but if your application is complex, if your users needs to save files, share files or have system wide menus and a proper security context – then the idea here is that you can deploy to the desktop system.
The IDE will then include the pre-compiled code for the desktop architecture, and you can run the whole thing on your company server. This gives you much better security and fine-tuned control over what each customer can do. You can even rent out storage space if you like.