
Text parsing is something most people rarely think about. We mostly work with file formats that already have existing parsers – be it JSON, XML or Inifiles. But there are edge cases where knowing how to properly parse a custom format or string can make all the difference.
In this article I will cover the essential architecture of the Quartex parser, the default parser for the Quartex RTL and our native framework. This framework is the codebase we wrote to implement the IDE for Quartex Pascal, and it contains a wealth of useful units. The Quartex native framework will be available to backers and customers shortly after release of Quartex Pascal.
Some background
The most difficult part of implementing a new development toolchain and RTL, is that you literally have to implement everything from scratch. In our case we compile object pascal to Javascript, which means that very little of the infrastructure we know from Delphi and Freepascal exists. At best you can write a thin wrapper that use features from the JavaScript runtime (if applicable), but when it comes to more complex functionality – you have no choice but to write it from scratch.
Since Quartex Pascal targets node.js / deno, being able to work with ini-files is useful for things like server configuration. Json is great and i could have used that, but I wanted to make the RTL as compatible as possible (or at least offer similar features to Delphi and Freepascal), so I ended up taking ‘the hard way’.
Concepts and approaches
The first two iterations of my parser were a bit rough around the edges. They worked fine, but I always ended up exhausting their design and getting frustrated, so eventually I ended up writing a new one. It was only when i reached the third revision that I finally had a mold that was flexible enough to cover all the use cases I had encountered (with includes the LDEF language parser). It seems so simple and obvious when I explain it below, but a fair bit of work went into this (and yes I realize that the model i arrived at is not new).
What I ended up with was a parsing model consisting of 4 elements that are largely decoupled:
- Buffer
- Model
- Model objects (optional)
- Context
- Parser
- Parser collection (optional)
The Buffer
The buffer class is where whatever text you need to parse is held. The buffer exposes basic functionality for traversing the text (the parser is forward only, with some exceptions). Much like a database table it operates with a BOF, EOF and Next() cursor mechanism (you call the Next() method to move forward by one character). All methods are inclusive, meaning that reading or comparing always includes the character where the imaginary cursor is located. The current character can be read via the current: char property.
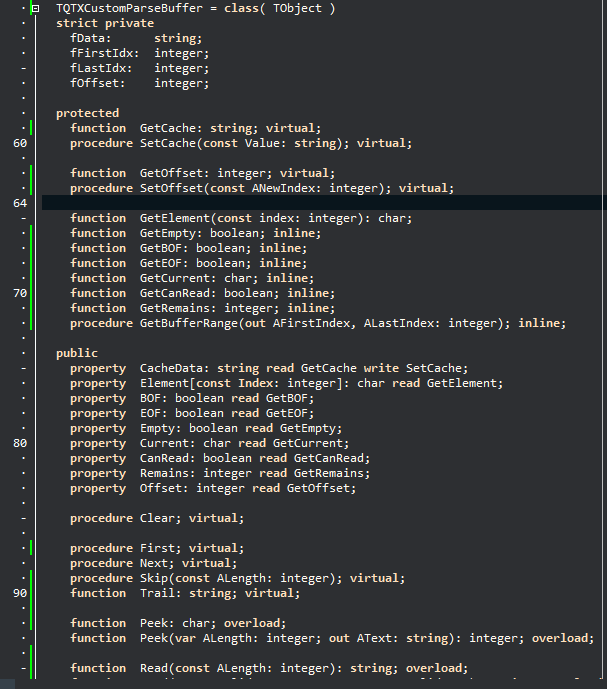
The idea of ‘inclusive reading‘ might sound like a trivial thing, but you wont believe the mess if you have functions that deviate from that exact same behavior. It seem absurdly obvious, but when writing loops and recursive code, finding that one scenario where you called Next() once to often is tricky.
The buffer builds up more complex behavior such as Read([length]), ReadWord(), ReadQuotedString(), ReadUntil(), Skip(count), Peek() and Compare(char|string). The most common comparisons such as equal, punctum, space, PasQuote, CQuote, less, more and so on – are isolated in a child class. This means you can write code that is quite readable and easy to maintain:
// move to the first char
buffer.first();
// Check that we are not BOF
// That would mean there is nothing to work with
if not buffer.BOF then
begin
repeat
if buffer.common.equal() then
begin
// we found the equal char
end;
buffer.Next();
until buffer.EOF;
end;
The above mechanism of EOF / BOF works well with Pascal strings that start at index 1. BOF evaluates as offset < 1, while EOF evaluates as offset > length(text).
The buffer operates with a few sub concepts that should be known:
- Ignore set
- Line ranges (optional)
- Bookmarks
- Control characters
These are very easy concepts:
- Ignore characters are set to [space + tab], this means the buffer will just skip them when you call buffer.ProcessIgnore().
- Line ranges means that the parser keeps track of CR+LF and register where each line of text starts and ends within the text (the offset into the string). The text you assign to the buffer is kept as a stock string field. There was little to gain by using pointers since an integer offset into a string is pretty fast.
- Bookmarks stores the current cursor position, column and row, and the current line ranges. Bookmarks are typically used when reading ahead to check something, so that you can quickly return to the previous state.
- Control characters are set to [#13,#10] (on Windows, Linux operates with #10 by default), the buffer will skip these and update the line-ranges when you call buffer.ProcessCRLF.
- Both ignore characters and control characters can be changes (type is TSysCharSet)
The model
Where the buffer provides the essential means of navigating through the text, you also need a place to store the result. For example, if you are parsing pascal code then you would identify keywords, parameters, brackets, semicolon and so on – and store these as tokens somewhere (the tokenizing stage of the compilation process). This ‘somewhere’ is where the model object comes in.
Example:
With ini-files the two entities we collect are groups, such as “[settings]”, and name-value-pairs, like “port=8090”. Differenciating between these are simple, as group names are within brackets [], while value assignments contains a = character beyond column position 1. Checking that the criteria for a value is met means reading ahead and looking for “=”. The name will be to the left of the equal char, and the value is whatever is beyond it. CR|LF is a natural stop, making inifiles simple and elegant to parse.
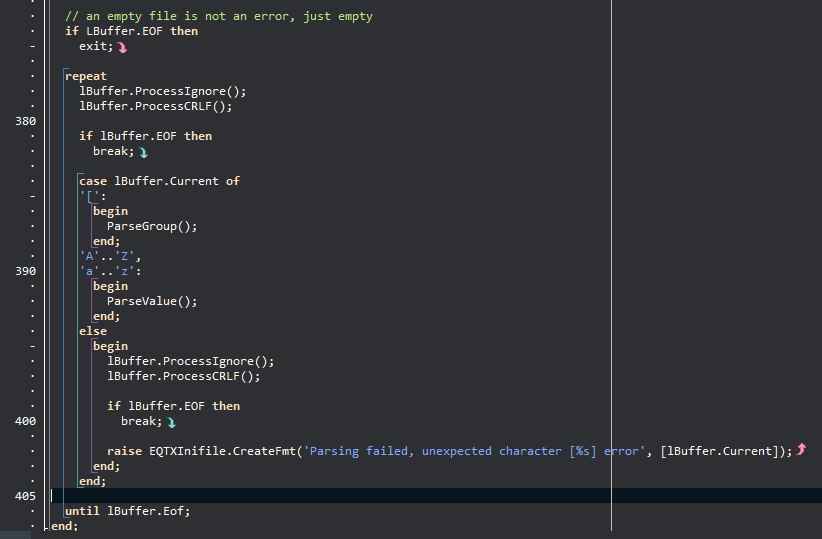
You are expected to inherit from TQTXCustomModel and setup whatever data structure you need there. So the parsers that I already implemented, such as TQTXInifileParser, TQTXCommandlineParser, TQTXDFMParser and so on – all have a specific model, context and parser classes.
The context
This is where things become more interesting. When you are dealing with truly complex formats, be it source-code or something of equal complexity, you can write several parsers that deal with a particular chunk of the format. So instead of having one massive parser that is supposed to deal with everything under the sun – you divide the work across several parsers instead.
To make this easy and fast, both the model and the buffer is isolated in the context object. The context object is the only piece that is shared between parser instances. When you create a parser, you must pass a context instance to the constructor. Since the parsers use the same context (and consequently buffer), you can create parsers on demand and continue in your main loop without problems.
The parser
The parser class is where you implement the logic for either an entire format, or a piece of a format. You use the methods of the buffer to work your way through the text, store whatever results you have in the model – and create sub parsers should you need them. Since no data is stored in the parser itself, not even the position in the buffer, they can be recycled easily.
For example, if you were parsing a pascal unit, you would have a parser for the interface section, one for the uses clause, enum parser, record parser, class parser, interface parser, function and procedure parser, var parser, comment parser – and then use them at the correct places.
Recycling parsers this way is why we have a parsing collection available.
Parsing collections (optional)
Sub parsers (as mentioned above) can be held in a dictionary like class, TQTXParserCollection, so you can query if a parser exists for a given name or token.
var lKeyword := context.buffer.ReadWord();
if fParsers.GetParserInstanceFor( lKeyword, lSubParser) then
lSubParser.Parse( context )
else
raise EParseError.Create('Syntax Error');
end;
Availability
The latest parser framework will be available in the next update. It has been re-implemented from scratch to work with QTX (first and foremost), Delphi and Freepascal.
As of writing the use of the code outside of QTX is reserved for backers / customers, we might consider making it open source together with the Quartex Native Framework after the release of QTX.